Introduction
As some of you might have noted I tweeted that I liquidated a long TAO position on December 27. Pulled the trigger at 314, and the price is now 235 as of writing.
This was of course partly luck, and market beta but heavily informed by the work of our new Team Member, IridiumEagle - who is tasked with fundamentally researching AI coins. He holds a pHD in CS, and was the CTO of an AI focused start-up in the biological computation space. He’s new to crypto. Below is our report detailing a neutral view on TAO. We are extremely excited about AI coins (as per earlier posts), but as great as it would be to “left curve it” and just buy everything we’ve quickly realized that we need stronger fundamental views to hold investments through losses.
This report is technical and market commentary not a recommendation to buy or sell securities or commodities and we have no relationship with the Bittensor, TAO or associated teams that would encourage positive or negative statements. Please consult our Disclaimer Disclaimer
Executive Summary
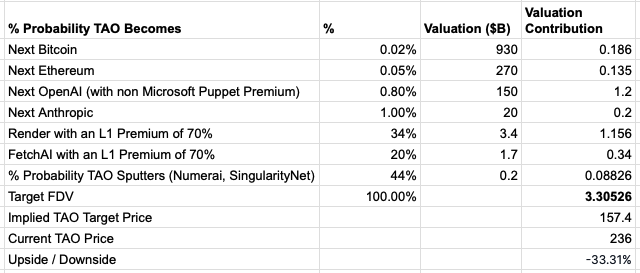
At a maximum supply of 21 million with a current price of 236, TAO has a Fully Diluted Value of $5b. While this is appealing relative to the potential TAM of AI coins - it’s hard to justify owning the coin due to a large delta between what they assert to be true in their whitepaper versus the reality. This gives us relatively low weights to assign to extreme upside valuation scenarios that TAO replaces OpenAI.
The biggest problem with TAO is that it (as far as we can tell) encourages collusion and runs on a fairly opaque basis which makes the protocol difficult to use.
Rather than owning TAO outright we are providing “intelligence” to the TAO Network to complete Text Prompting queries. We feel this gives us optionality on future Airdrops and network usage such that we might revise this thesis at a later date. We are aligned with the success of the TAO Network and as the assumptions behind this valuation table change, we would revise our risk reward of owning the coin accordingly.
Even a 3% chance TAO could become an Open Source version of openAI would justify heavy investment, but given the current state - this does not seem believable. In the near term it is possible we may be long TAO as a trade into likely exchange listings which are delayed by complex configuration with L1s - but this would fundamentally be (for now) short term speculation rather than a view on accrual of network value.
If anyone at the TAO Team wants to chat with us to clarify anything in this report, please e-mail [email protected]
What is TAO?
Tao is a cryptocurrency representing the BitTensor network. Tao argues that it is
- A language for AI systems to interact with one another
- A connector between compute, data storage and AI calculations
- A digital commodity
The BitTensor network defines itself as follows:
“essentially a language for writing numerous decentralized commodity markets, or ‘subnets’, situated under a unified token system. These distinct markets function through Bittensor’s blockchain, allowing each to interact and join into a singular computing infrastructure. By analogy, Bittensor brings the same type of abstraction which Ethereum added to Bitcoin for running decentralized contracts, but onto Bitcoin’s inverse innovation — digital markets.”
The latter sentence is drawing a parallel between how Ethereum expanded the utility of Bitcoin’s blockchain technology, and how
Bittensor is similarly expanding the concept to encompass a wider range of digital markets, beyond just currencies or contracts. Bittensor is posited as a platform that enables the creation and interaction of multiple decentralized digital commodity markets under the same overarching framework.
They claim that their network design supports all sorts of computing: “Building a hierarchical web of resources, ultimately culminating in the production of intelligence; intelligence leverages computation, which leverages data, which leverages storage, then finally leveraging oracles and data procurement and into infinity, all within the same ecosystem.”
They also claim that this is done in a manner that empowers folks with fewer resources, with a goal to: “ensure that the benefits and the ownership of machine intelligence are in the hands of mere mortals.”
In various writeups, the creators of BitTensor are keen to point out that they are merely an overarching market framework that supports decentralized varieties of service products for computing that we currently experience as centralized.
Later on, to unpack this claim we will look at the major types of centralized computing service products on offer today and assess whether BitTensor would be applicable. These could include storage and file sharing, collaboration tools, email services, database management, development platforms, virtual desktops, backup and disaster recovery systems, content deliver networks, network management tools, security and compliance tools, and integration platforms. If BitTensor is a universal computing platform, then its core framework is going to have to support use cases like the above.
Before we get there, let’s evaluate some of the claims that BitTensor makes as it explains its philosophy. Some of these are quoted below:
“In summary, digital commodity incentive mechanisms are the perfect markets, and perfect markets have the amazing quality that, when aligned, they are unstoppable and unequivocally powerful”
“the Bittensor paradigm is about being a network, computer and language for writing systems, alongside the market which created Bitcoin’s gargantuan size. However, they fundamentally differ in how they use these resources. Where Bitcoin simply secures its network by creating one trivial product (namely SHA-256 Hashes - which are unusable and not readily transferable into any real problem), Bittensor doubles down, allowing the building of multiple intertwined and complementary sub incentive systems, which build out commodities, like data or bandwidth, with real-world, applicable value, culminating ultimately, in intelligence.”
Is this a fair summary of Bitcoin’s power, and is BitTensor as described so far analogous? One comparison that is not mentioned, but that is important, is Bitcoin is trustless, by design. Even if you wanted to ‘cheat the system,’ you cannot, because it is not currently mathematically possible to do so without compromising the usefulness of the ledger itself. This is important, because it puts an unshakeable bedrock underneath the coin; a given Bitcoin definitely represents the past expenditure of a certain amount of computing power. BitTensor’s claim is subtly, but importantly different, namely that it represents outputs that its market participants value.
In other words, if we’re defining Tao, a Tao is a measure of smoothed subjective preference on its network, whereas a Bitcoin is a measure of an objective compute operation. Importantly, the authors of the About page for BitTensor state “Bittensor is like Bitcoin in many ways. It has a transferrable and censorship resistant token, TAO, which runs on a 24/7 decentralized blockchain substrate which is auditable and transparent.” As we will see, there are actually five major claims embedded in this statement.
The claims are as follows:
- Tao is a transferable
- Tao is a censorship resistant token
- The BitTensor network is decentralized
- The BitTensor network is auditable
- The BitTensor network is transparent
If these claims hold up, then indeed, Tao has many similarities to Bitcoin, and may enjoy some of its significant advantages in spite of its fundamental difference in premise. As well, if these claims are valid, then it may be possible to believe that the network’s existence will lead to a flourishing of open machine learning technologies accessible to and attainable for the great unwashed.
If these claims are not true, then the overall story becomes difficult to believe, and of course the actual network design must be subject to analysis to predict likely outcomes. The devil, as always, is in the details, so in the next few sections we’ll go under the hood and look at those details since various papers and repositories are available.
Using TAO
Installation
Before making further statements about TAO we decided to try and use its platform and evaluate its success getting traction. The BitTensor network documentation specifies that a node must have a minimum of 8gb of VRAM, and 20mbps upload and 100mbps download capability. These are surprisingly light requirements for either inference or training.
First, we will need to install the bit tensor wallet application. The steps are here python3 -m pip install –upgrade bittensor btcli –help Now we create a wallet, following https://docs.bittensor.com/getting-started/wallets btcli wallet new_coldkey –wallet.name usertest-coldkey
We create a mnemonic for the cold key, which is: track pool skate regular reject that shift marine parrot kit retire hamster
We create a password for the cold key is : REDACTED
btcli wallet new_hotkey –wallet.name usertest-coldkey –wallet.hotkey usertest-hotkey
We create a mnemonic for the new hotkey, which is: REDACTED
Assuming you’re running on a Mac and you have homebrew, you must then install the tree package. brew install tree
Mac-mini-5:~ Neo$ tree ~/.bittensor/ /Users/Neo/.bittensor/ └── wallets └── usertest-coldkey ├── coldkey ├── coldkeypub.txt └── hotkeys └── usertest-hotkey
We will attempt to register on the network via proof of work registration: btcli subnet register –netuid 3 –wallet.name usertest-coldkey –wallet.hotkey usertest-hotkey
Unfortunately, proof of work registration did not appear to function correctly. Also, the alternative would have cost ~$120 in TAO at the time of this writing, and would not have guaranteed that our node would stay up. Therefore, we follow the “all local” guide, listed (here)[https://github.com/steffencruz/ocr_subnet/blob/main/docs/running_on_staging.md]:
Once everything was installed on the server, the way to run a local node was via :
username@username3:~/subtensor$ BUILD_BINARY=0 ./scripts/localnet.sh Now, when running the local net, if you follow the tutorial and run the command: btcli subnet create –wallet.name owner –subtensor.chain_endpoint ws://127.0.0.1:9946
In order to create a subnet, then you will get a failure message along the lines of : Your balance of: τ300.000000000 is not enough to pay the subnet lock cost of: τ1,000.000000000
In order to generate the subnet, I needed to run the faucet function for the owner 4 times. The functions generated 300 T each time, rather than 100 T, for some reason.
Running the faucet produced output something like this: (tpython) username@username3:~/bittensor-subnet-template$ btcli wallet faucet –wallet.name owner –subtensor.chain_endpoint ws://127.0.0.1:9946
Run Faucet ? coldkey: ____ network: local [y/n]: y
Enter password to unlock key: ⠇ Solving Time Spent (total): 0:00:07.904206 Registration Difficulty: 1.00 M Iters (Inst/Perp): 76.9KH/s / 75.9KH/s Block Number: 412 Block Hash: b'0xa9387394d5c0553e3c7199e355ed2a35989adfe076ce790a470e17a68d6a539d’
I created a subnet, but when trying to register a miner with it, I encountered another error, as follows:
Error: argument subcommand: invalid choice: ‘recycle_register’ (choose from ’list’, ‘metagraph’, ’lock_cost’, ‘create’, ‘pow_register’, ‘register’, ‘hyperparameters’)
Changing the command to use “register” instead of recycle register allowed it to run, but then the miner had an insufficient balance, so I was forced to use the faucet for the miner as well. Once I gave the miner some tao, the command ran successfully, as follows:
(tpython) username@username3:~/bittensor-subnet-template$ btcli subnet register –wallet.name miner –wallet.hotkey default –subtensor.chain_endpoint ws://127.0.0.1:9946 Enter netuid [0/1/3] (0): 1
Your balance is: τ300.000000000
The cost to register by recycle is τ0.500000000
Do you want to continue? [y/n] (n): y
Enter password to unlock key: Recycle τ0.500000000 to register on subnet:1? [y/n]: y 📡 Checking Balance… Balance: τ300.000000000 ➡ τ299.500000000 ✅ Registered (tpython) username@username3:~/bittensor-subnet-template$
After completing all the commands, we have registered a local miner and a local validator on our local subnet. Running the miner python file produces expected output, but also an error:
2023-12-25 04:02:25.399 | INFO | Miner starting at block: 556 Exception in thread Thread-3 (run):
Traceback (most recent call last): File “/usr/local/lib/python3.11/threading.py”, line 1038, in _bootstrap_inner self.run() File “/home/username/pyvirtual/tpython/lib/python3.11/site-packages/uvicorn/server.py”, line …RuntimeWarning: Enable tracemalloc to get the object allocation traceback Running the validator also produces an error: 2023-12-25 04:05:30.974 | ERROR | Error during validation Sample larger than population or is negative Traceback (most recent call last):… raise ValueError(“Sample larger than population or is negative”) ValueError: Sample larger than population or is negative
I ran both files in parallel in different screens. The validator would not do anything without a miner running, which makes sense I suppose.
Examining the Templates
The example contains two templates, one for a miner, and one for a validator. Both templates are written in standard Python. Let’s look at what functionality is described in each template.
Miner:
This is a class that is used to define the behavior of a miner. It contains some functions that seem to be intended to be overridden. The first function, forward, is defined thus: async def forward( self, synapse: template.protocol.Dummy ) -> template.protocol.Dummy:
In other words, it takes as an input a dummy value, and emits a dummy value.
In the case of this function, the output is simply multiplied by two. The function has no other requirements except that it takes this input and emits this output.
The next function, blacklist, blacklists requests that meet user defined criteria: async def blacklist( self, synapse: template.protocol.Dummy ) -> typing.Tuple[bool, str]: The user is advised to use the provided api to look at the ‘credibility’ of the calling entity, and to reject its requests if it does not have a stake or is not a validator. The next function, priority, describes how the miner prioritizes requests, and is defined as : async def priority(self, synapse: template.protocol.Dummy) -> float:
In the example, entities with higher stakes get higher priorities.
For a given miner, these are the only functions that are mandatory to be implemented. Validator:
This example is even simpler. The only function stub defined is async def forward(self): """ Validator forward pass. Consists of: - Generating the query - Querying the miners - Getting the responses - Rewarding the miners - Updating the scores """ # TODO(developer): Rewrite this function based on your protocol definition. return await forward(self) It is clear that in the example, this doesn’t really do anything. It is odd therefore that the writeup of the overall example claims that it should be rewarding the miner. This example will never issue any rewards.
Examining the Full Tutorial
Now that the wallet is created, we will follow the latest tutorial published, on OCR, located here
This tutorial claims to get us up and running with a network focused on optical character recognition, defined by three files. The first file is the protocol file.
The whole protocol is defined in 45 lines or so, and essentially says that the input is a base 64 image, and the output is a list of dictionaries. There isn’t much more to it than that.
The next file is the miner
The miner’s initialization function specifies its forward, blacklist, and priority functions and sets some configuration parameters. As mentioned in the documentation:
This function performs the following primary tasks: 1. Check for registration on the Bittensor network. 2. Starts the miner’s axon, making it active on the network. 3. Periodically resynchronizes with the chain; updating the metagraph with the latest network state and setting weights.
Essentially, these operations are fully accomplished by use of the api. The only other code in the miner is the set weights function:
def set_weights(self): """ Self-assigns a weight of 1 to the current miner (identified by its UID) and a weight of 0 to all other peers in the network. The weights determine the trust level the miner assigns to other nodes on the network.
This seems like a pretty simplistic way of assigning trust. BitTensor does not seem to provide any out of the box tooling to make such judgements easier, which is one reason that its claims about new miners joining ‘good’ groups suspect. Since the miner didn’t contain any useful code, I was initially confused. Apparently, however, I was looking at the base class. The instantiation of the class is here
The main logic for this one is contained within the forward code block. Essentially, in this block, the pytesseract library is used to generate a series of bounding boxes on an image and attempt to convert it to text. The images for the tutorial are generated synthetically so that the validator will be able to deterministically evaluate the responses. The miner code is about 40 lines. The other functions are boilerplate similar to the templates. The validator scores miners based on text similarity to the synthetic data that it generated. The whole validation code is about 40 lines of code, though it uses utility functions that total perhaps 200 lines. Since this code seemed fairly rudimentary, I decided to crack open their other tutorial.
Key points are as follows: “The text prompting subnet works like this: The subnet validator sends text prompts to subnet miners and waits for the responses from the subnet miners.
After receiving the responses from the subnet miners, the subnet validator scores and ranks the responses from the subnet miners.
Finally, the subnet validator sends these ranks to the blockchain, where the Yuma Consensus allocates the rewards to the participating subnet miners and subnet validators.”
The following activity diagram is provided:
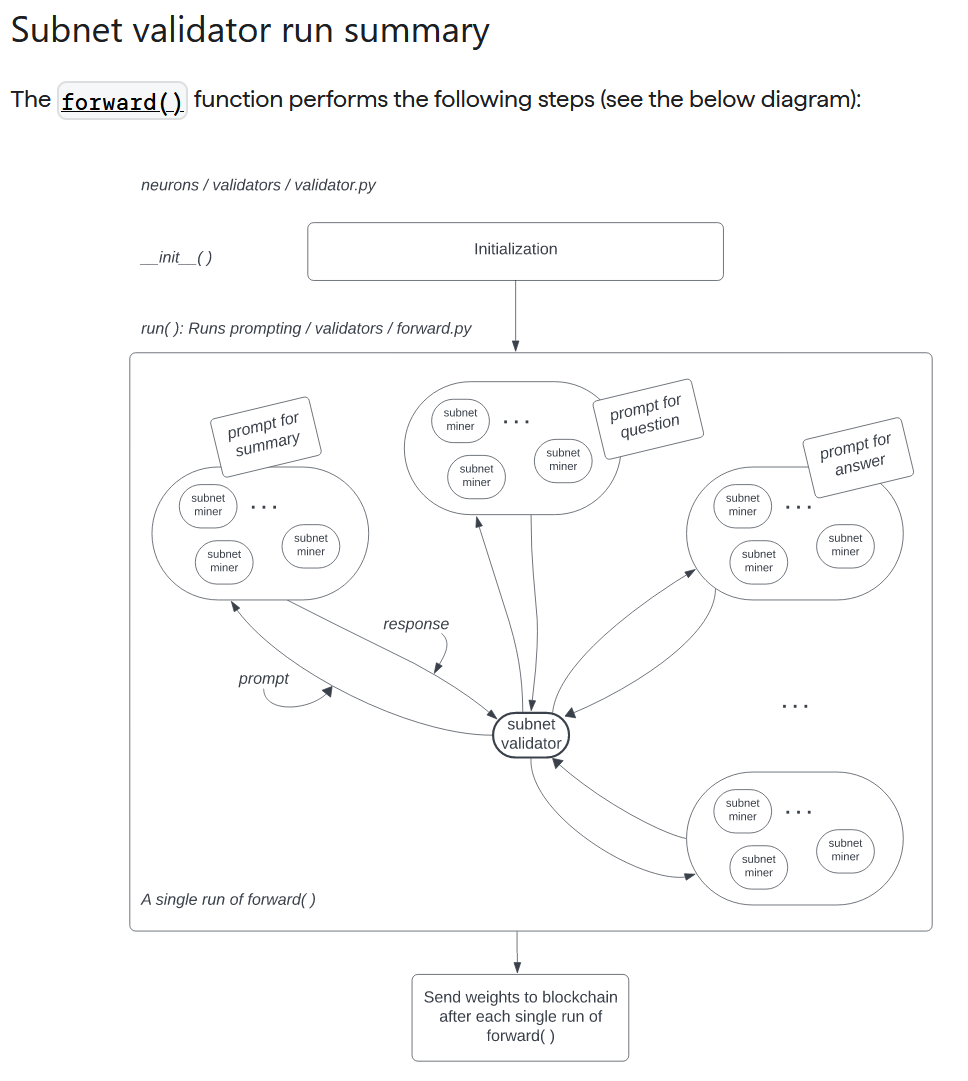
So, what seems to be occurring here is that the subnet validator sends out different prompts to different groups of miners, and then waits for the responses to come in such that these can be graded. The task being assigned around is related to the generation of summaries, questions, and answers for a given piece of text. This description accords with our earlier outlined understanding, wherein any given task has an overhead multiple of N, where N is the number of miners queried, and an overhead V where V is the time it takes the validator to work its way through all the responses.
The tutorial goes on to discuss a variety of other topics, generally not adding substantive information beyond what we learned in the OCR tutorial. One issue that is generally sidestepped (as discussed in the previous section) is around the capabilities required for a validator. Intuitively, you can imagine a situation where one of the miners is running a very powerful model. After all, the miners are supposed to have the most incentive to create winning responses, so they will have the most incentive to use powerful models. Is a validator running a less powerful model than a miner going to grade the powerful miner’s work favorably?
There is a paradox in the sense that BitTensor claims that the best models are organically going to dominate, but that is only true if the best models are also being graded by the best models. Any other outcome is going to be kind of random because an inferior model is not equipped to grade a superior model. This is true regardless of the ML problem domain being approached, unless the problem is constrained in a way that there is a known good output for a given query that the lesser model can score a better model against.
Even when such scoring referents are available, however, they don’t help a poor model do a better job of ranking novel responses, which is the task validators are supposed to be accomplishing.
Network Usage and Economics
Tao stats is a great resource for visualizing activity on the BitTensor network
The site outlines the various uses for TAO which includes many of the uses that you might associate with a tool like ChatGPT. Text and image generation, and scraping.
Let’s evaluate a few of the major subnetwork in turn and consider:
The concentration of activity around distinct cold keys
The miner incentive distribution (translated into dollars)
Starting with the Text Prompting subnet, the top earners look like, with the top earner producing $11k+ of revenue on a whopping $278m stake

The daily earnings in this case seem largely driven by stakes, and the top 3 earners are all validators. To decompose how much is actually earnable via computation rather than staking we have to go down the list.
Going to the middle of the pack of 1024 entries, we see the following:

The average miner in the mix is making $50 per day. Unfortunately, we don’t have any information on their costs.
Interestingly, the 151st miner is also making approximately $50 per day, suggesting that model performance is not particularly differentiated among these miners.

In fact, if we jump all the way up to position 28, that miner is only making $57 per day.
In fact, no miner is actually making more than $58 a day. All the other entries above these are validators, and a sort of middle of the pack validator is pulling in roughly $400 per day. This is an important point because if Subnets worked well you’d expect strongly different payouts. Miners in the subnet are highly concentrated among a few coldkeys, indicating that large players dominate this subnet:
Let’s jump around and look at another couple of subnets. Flavia and Cortex.t are popular (as in hyped subnets on BitTensor. A succinct description may be found here:
Let’s look at Flavia first.
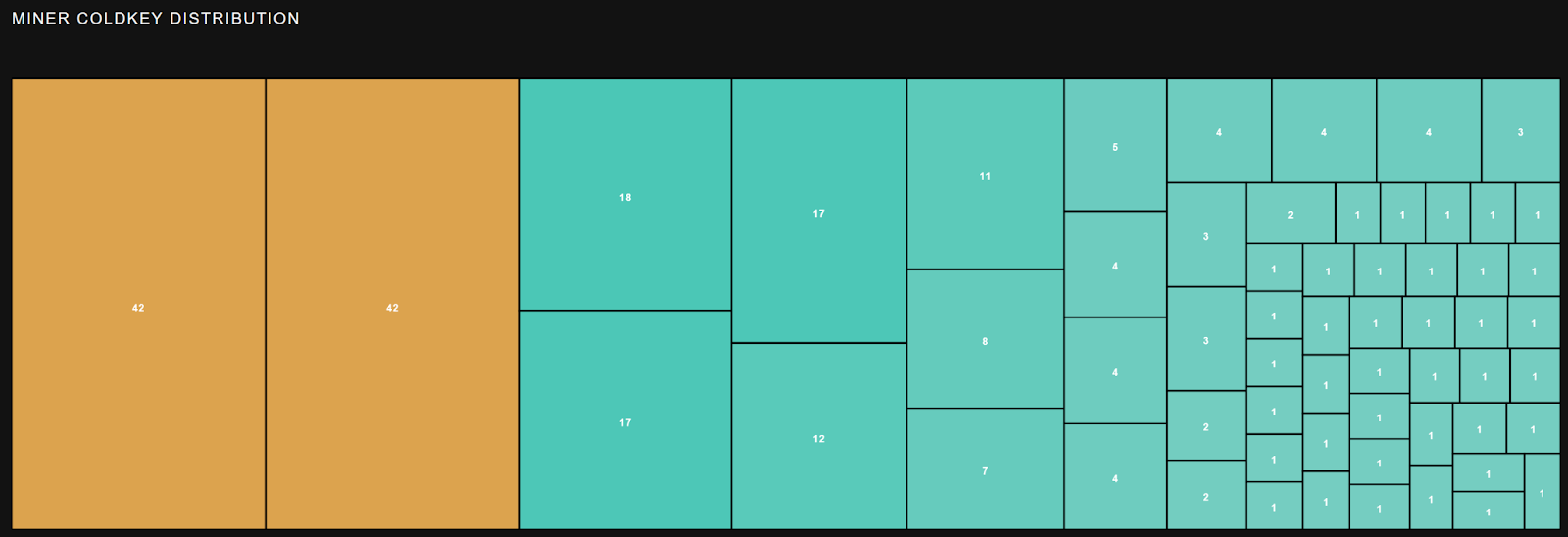
Roughly 9 entities control the vast majority of this network. The top three earners are all validators, and these are pulling in approximately $355-$499 dollars per day. The Middle of the pack (of 256) miners 128-130 are actually earning nothing. Miner 64 is earning about $29 a day.
The highest earning non validator miner is only earning $31.67 per day.
These numbers certainly do not lend themselves to the idea that the TAO network has heavy traction or that the subnets provide high differentiated edge that would incentivize further usage.
Let’s jump to Coretex.t, which has a coldkey distribution like so:
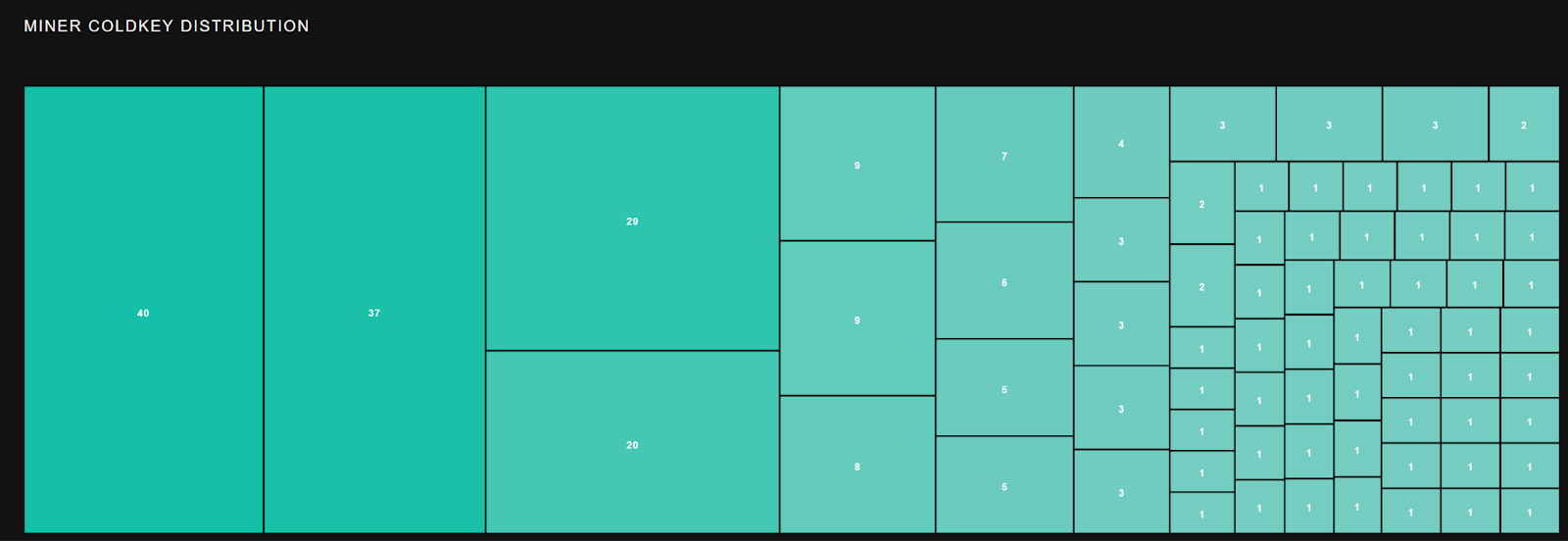
This is maybe slightly better than Flavia, but still pretty bad since ‘miners’ are basically performing OpenAI passthrough queries with extra steps, by design.
The top 3 earners are validators making bank on their stakes.
Middle of the pack is actually doing great at $450 per day. Weirdly, all of these miners have really low total $ though. It seems like high miner churn might be a factor here, as might be expected given that it’s harder for miners to differentiate themselves with passthrough queries.
What is BitTensor, technically, and what value does it bring?
BitTensor is described technically across a white paper, a conference paper, technical documentation pages of varying levels of detail, and of course most literally, by its own code. What follows is an attempt to scrutinize the technical description provided, the major claims made.
The BitTensor About page emphasizes a few key points:“Arguably, Bittensor’s core technological innovation is the separation of the chain’s core functioning (transferring funds etc.) from the running of the validation systems which define the markets for its digital commodity creation. This is distinct from Bitcoin, Ethereum, Filecoin and most every digital commodity system on the market today”
“Furthermore, all of the tools required for validating the subnet mechanisms remain off-chain, allowing them to be potentially extremely data heavy and compute intensive.”
“What makes this possible is Yuma Consensus (YC). Yuma Consensus is the mechanism Bittensor runs on its chain, to enforce that there is agreement between the validators of the individual sub mechanisms in Bittensor’s network. By analogy, Yuma Consensus is the central processing unit (CPU) of Bittensor. YC takes the varying incentive mechanisms written by developers and transforms them into an incentive landscape, whereby agreement is reached and miners are forced to act in the way defined by the people who write the consensus mechanisms for the individual subnets.”
There’s a lot to unpack in these few paragraphs, so let’s make an attempt to expand the implications, and then go into some of the details contained within their papers.
As mentioned in the previous section, the developers want to emphasize that they have created a flexible framework where rewards are apportioned by the community. They have separated the reward mechanism from the record keeping mechanism, and view this as a major innovation.
Of course, this change has some major first order ramifications, some of which are as follows: As validators and validation are off chain, there is no reliable way to establish trust in the system. Whereas in Bitcoin, it is not mathematically possible for miners/validators to cheat and make gains without controlling the network, in this system it is seemingly assumed that cheating will be punished economically.
There is no record of what process / computation occurred to produce a particular result, and no requirement to produce such a record. Miners / validators can be complete black boxes to each other.
There is no record of how validation occurs, or by what criteria rewards were apportioned. Validation techniques might be changed arbitrarily at the subnet level without notice.
No data used for ML training is actually stored on the blockchain network, temporarily or permanently.
No ‘progress’ can be made toward any specific goal, as by design, miners and validators are not required to share their models.
Since the validation layer is just software and is not fixed by the chain, in theory one could completely change the validation layer for a given subnetwork to be a pure token exchange without using any of the primitives provided by BitTensor. In a sense, an “AI” framework becomes merely a suggestion in this case.
Yuma Consensus enforces agreement but not correctness, as correctness cannot be known a priori based on the design of the network as one which supports subjective preferences
If the consensus is not enforced at the chain level, it may simply be ignored by a given subnet.
Unlike with Ethereum or many other coins, the incentive systems are not voted on by network participants, but implemented by fiat by those who have enough currency to stake. Thus, incentive systems in this network are fundamentally undemocratic.
Given that the network design itself does not enforce trust, an extremely high burden is placed upon network validators. This creates potential downsides that validators must perform a large amount of computation to maintain trust, or suffer potential output quality drops / cheats / hacks.
For a study in contrast, consider BitTensor’s design in relation to the elements classically understood to be part of “Trusted Computing”:
- Hardware-based Security: Trusted computing often relies on a hardware component known as the Trusted Platform Module (TPM). The TPM is a secure crypto-processor that is designed to carry out cryptographic operations. It includes multiple physical security mechanisms to make it tamper-resistant, and can securely store artifacts used to authenticate the platform (your PC or another device).
- Secure Boot: This is a process that ensures that only trusted software is loaded and executed on the system. It involves the verification of the digital signature of each piece of boot software, including the bootloader, kernel, and base operating system. Root of Trust: Trusted computing establishes a “Root of Trust,” which is a set of functions that is always trusted by the system. The Root of Trust can be established through hardware (like the TPM) and is used to verify other components of the system.
- Software Integrity Verification: This principle involves checking if the software has been tampered with. If the integrity check fails, the system can take appropriate action, like preventing boot or running in a restricted mode.
- Data Protection: Trusted computing ensures that data stored on the computer is encrypted and only accessible to authorized users. Encryption keys can be stored in the TPM, making it more secure than software-only solutions.
- Attestation: The ability of a device to attest to its identity and the integrity of its software and hardware configuration. This can be used to ensure that a system is secure before connecting it to a sensitive network. Least Privilege: Ensuring that processes and users have only the minimum privileges necessary to perform their functions, minimizing the potential damage from exploits or malware.
In BitTensor’s case, hardware remains unknown, it is a service level abstraction. Secure Boot is irrelevant as no software being executed is signed. Root of Trust is arbitrary and determined by the subnetwork operator. Software Integrity Verification does not occur. There is no data protection. There are no attempts to enforce any system of privileges at the chain level, and since the software layer is malleable there is effectively no privilege enforcement.
Now, you may reasonably argue that with a cloud service provider, it is impossible to know how secure the environment is according to these criteria, without specific guarantees / audits being provided. That is certainly true.
Consider, however, that these service providers are bound by legal agreements and liability, which constrains their actions. With BitTensor, there is no trust, no enforcement, and no recourse if something goes wrong. Under such circumstances, it is probably wise to ask: What kind of jobs would I run on such a network? Would I be able to guarantee quality of service for my own purposes or to my customers?
We will return to these types of questions and network design ramifications when we start to evaluate the various claims. For now, let’s take a diversion and look at a conference paper BitTensor published, as well as their white paper.
Conference Paper
BitTensor (BT) is a network premised on the idea that AIs grade each other and tokens are allocated accordingly. BT’s conference paper (https://bittensor.com/pdfs/academia/NeurIPS_DAO_Workshop_2022_3_3.pdf) starts with a glancingly brief standard literature review, which quickly makes some bold assertions, such as the following (about the history of machine learning as a whole): “However, since intelligence produced by these models is always lost, this approach is quite inefficient.
Users have to retrain models on their own systems to replicate, or improve upon, the work of others. Consequently, this leads to unnecessary computational loss in learning tasks that other models have already learned”
The reason that this statement is bold is that it presupposes that task learning of neural networks could be usefully portable across datasets, architectures and contexts; this has not yet been achieved.
Given what we know about the design of the network (all computation occurs off-chain and is basically fungible), this also seems like a strange angle to take. If nothing is being archived by design, how is this network any different than the status quo of existing closed / inaccessible models in terms of knowledge loss?
The paper also asserts that model evaluation is currently primarily academic rather than real world, and offers the contention that :
“There must be a more efficient and objective method to evaluate AI model performance” The paper then launches, similar to the “About” page, into a description of a crypto network design intended to solve distributed model evaluation. The architecture is two layers, an “AI Layer” and a “Blockchain Layer.” This description is a bit more detailed than what was listed in “About,” so we will dive in.
AI Layer
In the “AI Layer,” each ‘node’ is a neural network, with the network weights for a given node being stored on the blockchain.
Without going into any technical detail about how it might be possible, the paper asserts that nodes individually and collectively will be able to perform inferences and back propagation.
Supposedly, nodes are connected by “synapses” which perform data formatting and sanitization according to unspecified “correct” schemas.
A series of diagrams describe what is essentially a standard machine learning process with some extra steps involving connecting models to each other and each node evaluating other nodes’ “informational value,” in an unspecified way. Without explaining how, the paper also asserts that the architecture involves a mixture of experts that is weighting node contributions.
The AI layer discussion seemingly ignores the major issue with implementing any large scale classical neural network architecture in this fashion: latency and network transport reliability. It also badly underspecified how this network corresponds to a Mixture of Experts architecture, and does not cover how extremely large data sets could be integrated into this network.
Blockchain Layer
The paper asserts that the AI layer is running in a separate process as compared to the blockchain layer, and that they communicate using system memory or via messages (some form of interprocess communication). The blockchain is based on an existing chain called the “Polkadot Substrate.”
In this scheme, nodes rank other nodes based on their usefulness, and 50% of nodes must vote that a node is trustworthy in order for it to receive rewards.
It then goes into a standard blockchain discussion of the warring generals problem. It describes algorithms by which value is allocated (the Shapley method), and asserts that scores using large language models of various sizes on the network have already been calculated. The network is sharded for scoring to complete, as scoring the whole network would be computationally intractable.
The paper then makes the following assertion regarding the current state of the network: “The Bittensor network officially launched in November 2021. As of writing this paper, the network contains 4096 peers; all of which are running a language model that is actively querying others for information or serving requests from other peers on the network. With a total sum of 500 Billion parameters running across 4096 peers, it is possible to query and infer from every node in the network and receive an output of logits, embeddings, or plain text responses given a prompt. Each peer is either running a custom language model, or a pre-trained model such as GPT-J (Wang and Komatsuzaki [2021]), GPT-Neo, (Black et al. [2021]), or GPT-2 (Radford et al. [2019]) downloaded from HuggingFace API (Wolf et al. [2020])’
Crucially, this statement is easily testable along multiple dimensions. When we look at evaluating the system in practice, we’ll pose queries to the text generation subnet.
The team also makes the following statement: “The Bittensor team is now training more sophisticated models directly on the Bittensor protocol to work towards achieving performance comparable to current state of the art models.”
This statement should also be fairly straightforward to empirically verify, viz a vis an analysis of published validator / miner code.
Before we go into the practice, however, let’s go over the BitTensor whitepaper to see if we missed any crucial aspects of the theoretical design of the network.
Whitepaper
The whitepaper starts off with a brief abstract, including the following claim:
The Three Contentions
“Scores accumulate on a digital ledger where high ranking peers are monetarily rewarded with additional weight in the network. However, this form of peer-ranking is not resistant to collusion, which could disrupt the accuracy of the mechanism. The solution is an incentive mechanism that maximally rewards honestly selected weights, making the system resistant to collusion of up to 50 percent of the network weight. The result is a collectively run intelligence market that continually produces newly trained models and pays contributors who create information theoretic value.”
While this sounds good in theory, we understand that based on the design of the network, it is not actually necessary to control 50% of the network weights to disrupt the network. Rather, one may meaningfully disrupt the network by controlling more than 50% of the stakes allocated to a given subnet, possibly even less based on how a given reward algorithm is designed. This represents a further jettisoning of the sort of safety guarantees one might get with Bitcoin or Ethereum, and should make network attacks much less expensive. Since validator code is unverified, it should be possible to make “poison pill” validators that suddenly change behavior, completely breaking any given incentive scheme if the majority of trusted validators on a given subnet collude.
In the introduction, the whitepaper also states: “By changing the basis against which machine intelligence is measured, (1) the market can reward intelligence that is applicable to a much larger set of objectives, (2) legacy systems can be monetized for their unique value, and (3) smaller diverse systems can find niches within a much higher resolution reward landscape.”
The first contention is probably true if the market is open. If however, the market is controlled by a small group of early adopters, it seems less plausible that true customer demands will be reflected, but rather the interests of the first movers.
The second contention rests heavily on the definition of unique value. Is anyone using GPT-J if they have the option to use Mixtral or Llama 70b? Is anyone using legacy image classification models just for fun, when more accurate alternatives are available? It seems like machine learning is currently a “winner takes all” battleground split into “open weights run at user’s cost” and “proprietary weights run as a subsidized service by a large corporation” camps.
The third contention holds true only if niche models can charge a premium. If niche model rewards are distributed only according to popularity or staking, then they will necessarily be limited compared to those associated with generalist models. As well, niches in this case should be easier to attack with smaller stakes.
In the “Model” section of the whitepaper, it makes the following contention: “In this paper, we suggest this can be achieved through peer-ranking, where peers use the outputs of others F(x)=[f0(x)…fn(x)] F(x)=[f0(x)…fn(x)]as inputs to themselves f(F(x)) f(F(x))and learn a set of weights W=[wi,j] W=[wi,j]where peer i is responsible for setting the i th row through transactions on a digital ledger.” Confusingly, this seems to suggest a setup wherein miners (peers) are evaluating other miners. This is mostly not true, as the validators seem to be the primary entities determining reward allocation although as we will see later, miners can allocate ‘bonds’ to peers, etc.
The model section elaborates on the mechanism by which nodes are established as trusted: “We define peers who have reached ’consensus’ as those with non-zero edges from more than 50 percent of stake in the network. (This is simply the normalized values of (TT⋅S)>0.5 (TT⋅S)>0.5). To ensure the mechanism is differentiable we define this computation using the continuous sigmoid function. The sigmoid produces a threshold-like scaling that rewards connected peers and punishes the non-trusted. The steepness and threshold point can be modulated through a temperature ρ and shift term κ.”
Essentially, the idea being expressed is that “trust” values are stored in a matrix with a rater and a rated entity, and if the entity being rated isn’t connected to enough staked-in raters, then it is not trusted. The base assumption is, of course, that those with a large stake are to be trusted.
In a situation where all the computations are fully obscured, there is no inherent reason to adopt this assumption. We can compare this situation to that of Bitcoin - if the Bitcoin protocol is violated, then the network’s transaction ledger “breaks.” It is in the interest of the people who have invested in the currency to maintain the integrity of the ledger. In the case of BitTensor, no such disincentive for bad behavior exists.
If a smaller amount of tokens are issued to a miner than accord with the stated ‘rules,’ the situation that caused this cannot even be reconstructed because all transactions are off chain. There is no dire consequence for fraud in the network, because it doesn’t impact the actual transaction ledger. In the absence of any way to gather evidence, all that is left is “messaging.” We will discuss some actual scenarios in a later section.
In any case, the whitepaper next outlines a mechanism for making sure entities are actually producing “correct” weights. This involves the use of “bonds,” :
“Using the B bond matrix, the chain redistributes the normal incentive scores ΔS=BT⋅I ΔS=BT⋅ILike market based speculation on traditional equities, the peers that have accumulated bonds in peers that others will later value attain increased inflation themselves. Thus it makes sense for peers to accumulate bonds in peers which it expects to do well according to other peers with stake in the system - thus speculating on their future value. Finally, we adapt this mechanism slightly to ensure peers attain a fixed proportion of their personal inflation. For instance, 50 percent, ΔS=0.5BTI+0.5I. ΔS ΔS=0.5BTI+0.5I.ΔSbecomes the mechanism step update which determines network incentives across the n peers.”
If you’re reading this like I am, you may find yourself scratching your head. The stated goal is to incentivize “correct” calculations, but the mechanism of incentivization is simply to reinforce the preferences of existing stakeholders. These are not compatible concepts.
To make this crystal clear: Imagine that you are a validator. Your optimal strategy under this regime is to do what others do and support the work of currently popular validators, not answer correctly. If what others happen to be doing is useful, then that’s great, but the incentive of others is probably to “do the least amount of work possible to get a payout,” which is not driving correctness of results, either.
The model paper does a good job of outlining how a peer should behave in this network, with its influence balancing equations that are based on ‘correctness’ as perceived by the group. What it does not do is remedy the network’s flawed approach to modeling motive and incentive.
The white paper spends some time next on describing standardization of input and output formats, which is necessary to make the software work. Where the paper goes next is to an informative but entirely theoretical attempt to address the fungibility of its design (the problem that we expressed earlier as being incompatible with its goal of evolving ML models toward ‘intelligence’).
Essentially, the problem is : What happens if a good model drops off the network? Without a copy of the model’s weights, the knowledge is lost forever.
The solution proposed is a sort of half argument about how smaller models can use distillation techniques to learn to respond like larger models. While it is true that distillation can work under certain circumstances with less complex models, it is highly unlikely that it will work with more complex models and architectures that have been highly optimized in various ways.
If you’d like to prove this to yourself, ask why not every model is performing at the level of GPT 4 over a year after it has been released, when access to its outputs at a huge scale is readily available.
Furthermore, take away any financial constraints and consider that Google and Anthropic are still not at parity, despite the virtually unlimited resources at their disposal. A simpler argument around this argument is this: BitTensor does not build in sufficient incentives for true model distillation to happen and it does not have valid performance metrics to ever understand whether correct model distillation did occur.
If a model drops from BitTensor for whatever reason, and its creator doesn’t want it to come back and doesn’t release the weights, then it is gone. This paragraph is emblematic of BitTensor’s approach : It raises a very serious concern, only to handwave it away with the lightest possible recourse to a theory that explains how said concern could be addressed, while not addressing said concern in any meaningful way in the actual implementation.
The last paragraph is perhaps the most tenuous. It is a short proof that frames the problem of collusion in a way that dodges the core issue. The authors write:
“We assume that the proportion of stake in the honest graph is more than that found in the dishonest graph SA≫SB SA≫SBand that the chain has reached consensus L<0 L<0. Since all peers in B are disjoint from A, our loss term −RB⋅(CB−0.5)>0 −RB⋅(CB−0.5)>0is positive. Because L<0 L<0it must be the case that RA⋅(CA−0.5)<0 RA⋅(CA−0.5)<0is negative and there are peers in the honest sub-graph A who are connected to the majority."
Of course in this system design those with more stake will achieve consensus, that’s almost a tautology given that the equations are written into the code.
What is not a given, is that any new miner entering into the system will be able to identify ‘honest’ versus ‘dishonest’ nodes. What a miner will see is the popularity of individual nodes, not cabals. And because there is nothing forcing a miner to behave in any particular way, and it is costly to make judgments about other nodes, it is quite likely that an honest miner will join the ‘dishonest’ team.
The whole problem framing is written as if there is perfect information about the problem (which is closer to what you have on networks where the incentive structure is in code, or the contract code is on the blockchain), whereas in this network design there is literally no information about the decision structure of other nodes. We cannot pretend that staking and mining behavior will be rational and logical in an information vacuum. For all the whitepaper’s ranting about perfect capitalism, capitalism functions based on information and mental models of other actors. No such information need be present in this network design.
Finally, with respect to this proposed proof, consider that any new subnetwork that is started is going to be less capitalized with staking than any existing network unless one of the big holders started it. Said subnetwork can then be overpowered by literally any actor who holds more stake in the network, say, an attacker who specializes in tipping over smaller subnetworks. It could also be overpowered by a collection of smaller attackers who pooled their stakes. Are BitTensor’s claims believable and do they align with its value proposition?
In this section we’ll review the claims the network made, and whether those claims hold up. We’ve already covered some of these claims in detail so we’ll summarize the responses to those claims. We’ll also look at whether the network is fit for purpose for different types of applications, and what the likely behavior of the network will be.
Claim: Bittensor is the ETH of AI
Claim
“Bittensor brings the same type of abstraction which Ethereum added to Bitcoin for running decentralized contracts, but onto Bitcoin’s inverse innovation — digital markets”
Assessment:
Not true. Ethereum added a contract abstraction on chain. BitTensor is a non blockchain based scoring mechanism whose scores are stored on a blockchain. BitTensor fundamentally lacks traceability with respect to its reward mechanisms; it does not and cannot provide any guarantees about the fairness of reward issuance. Ethereum is a contract platform you can use without trust if you scrutinize the code of its contracts, but BitTensor is a market platform that inherently requires trust because the incentive mechanisms are obfuscated. To say that these things are analogous is disingenuous at best.
Claim: Tao Has the Potential to be a Full Stack AI coin
“[we are] building a hierarchical web of resources, ultimately culminating in the production of intelligence; intelligence leverages computation, which leverages data, which leverages storage, then finally leveraging oracles and data procurement and into infinity, all within the same ecosystem.”
Assessment:
Unlikely. BitTensor’s network design is fungible. Model weights are never recorded anywhere on-chain, so knowledge is not preserved. The preservation of knowledge is necessary for common work toward a goal like machine intelligence. Furthermore, the incentive structure of the network is such that it is advantageous for miners to keep their models, tools and techniques secret, as sharing these will result in a loss of rewards for a given miner.
Claim:
In various writeups, the creators of BitTensor are keen to point out that they are merely an overarching market framework that fully supports decentralized varieties of service products for computing that we currently experience as centralized.
Response:
To assess this claim, let’s look at some of the service products on the market today, and consider whether BitTensor brings desirable characteristics to the table.
- Storage and File Sharing: Services like Dropbox, Google Drive, and Microsoft OneDrive offer cloud storage solutions. They allow users to store files online, share them with others, and access them from any device with internet connectivity.
- BitTensor Storage and File Sharing: It is certainly possible to implement storage and file sharing on BitTensor, but such solutions also have the following undesirable properties: Data retention is not guaranteed. Since storage is not secured on chain, storage claims by miners must be constantly verified at great computational cost. This is particularly misaligned with storing machine learning data, which must be used repeatedly for training runs. Poor latency and throughput. Since the minimum requirements for a BitTensor node are incredibly low, it is unlikely that on average a network of such nodes will outperform even a basic NAS (network attached storage device).
- No standardized encryption / decryption protocol. Since BitTensor is only a framework for the subnetwork that implements storage, and lacks native encryption/decryption facilities, the subnetwork itself must implement such. This is not ideal, as it requires miners / validators / users to assess a cryptographic implementation, which has historically been fraught for non specialists.
- No standardized deduplication mechanism. Deduplication provides massive benefits to storage providers, but is notoriously difficult to implement well. BitTensor puts the full burden of developing deduplication on the subnetwork.
- Expensive / time consuming retrieval. Large amounts of data stored in a distributed way must necessarily be sharded. Machine learning applications run most efficiently when compute is closest to data. Storing on BitTensor all but guarantees that compute will be far from data, as these are on different subnetworks with different incentive structures.
Another angle to take is to look at what is on offer in terms of the CAP Theorem, as summarized by Wikipedia here:
- “Consistency Every read receives the most recent write or an error.
- Availability Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition tolerance The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.” From this standpoint, the BitTensor blockchain provides no primitives and no guarantees for data storage, and the framework doesn’t either. So, the network is completely unreliable. These are some of the theoretical considerations. We will spend some time later looking at the current storage solution implemented on the BitTensor network to judge whether it avoids any of these pitfalls.
With that said, the bottom line is that if something like Filecoin provides some guarantees with some tradeoffs, a BitTensor solution is going to just offer tradeoffs without any guarantees. To paraphrase the problem: “Why would I build a file sharing network on infrastructure I cannot trust while taking on a high overhead for verification and duplication?”
- Collaboration Tools: Platforms such as Slack, Microsoft Teams, and Asana facilitate team collaboration. They offer features like messaging, file sharing, task management, and integration with other tools.
- BitTensor Collaboration Tools: If it were easy to implement collaboration tools on BitTensor, they would probably be running on BitTensor rather than Discord. All the core problems from the storage side come along for this, along with an additional problem which is :
There is no obvious way for a non technical customer to interact directly with the network
Consider that most chat users are casual, and would not necessarily wish to stake money in order to chat. There is no easy way to onboard customers in this system. You could build a web service that handles everything, and somehow bridges to the BitTensor framework, but you also have to build a currency bridge in that case, so that users can pay you cash which you then convert yourself, or so that users can pay you other tokens which you can convert to use to buy stake in BitTensor network to increase your rewards to cover your operating costs and also to defend against network attacks.
Compare this to the alternative, which is that you rent a few servers you can trust from a reliable provider and accept cash via PayPal or Bitcoin for less overhead than would be required to get the same amount of compute from BitTensor, and BitTensor starts to look like a really bad deal.
Email Services: Examples include Gmail, Microsoft Outlook, and Zoho Mail. These services provide email communication, often with added functionalities like calendar integration, contact management, and file sharing.
BitTensor Email Services: About as problematic as chat, for the same reasons. Add the following problem: Since you need a domain name to send email from as an email service provider, you now have a central point of failure in the event someone seizes your domain, or bots decide to run an anonymous spam service through your domain.
Database Management: Services like Amazon RDS, Google Cloud SQL, and Microsoft Azure SQL Database offer database management systems. These allow users to create, manage, and scale databases without managing the underlying infrastructure.
BitTensor Database Services: Databases have to run unencrypted since homomorphic encryption (https://en.wikipedia.org/wiki/Homomorphic_encryption) isn’t really supported yet.
Would you trust arbitrary nodes on a fungible easy to attack network with any sensitive data? What would your customers think if they learned that you were sharing such data on such a network?
Would your customers tolerate random outages due to network resources randomly dropping?
How would you ensure consistency among databases? How would you treat lost writes? In a world where any database could drop at any time, how would you pick an authoritative database?
These are the basic challenges that a BitTensor database service would have to overcome.
- Compute: Platforms like RunPod, Vast.ai, Lambda Labs, Digital Ocean and many others provide compute for an hourly fee.
- BitTensor Compute: The BitTensor framework is structured to look at and verify the outputs of compute, not the compute itself. For example, validators in BitTensor send a request to multiple miners and have them produce responses that are graded. The top responders are rewarded, and presumably the top results are passed on to the customer. From a customer standpoint, there are thus a few important considerations: The amount of compute employed is some multiple N of the compute actually needed for a single response, because multiple miners are running the calculation. Furthermore, since a validator must grade all the responses or sacrifice quality, more overhead is added (N+V)
Either this multiple (N+V) is being subsidized by the network (unlikely, since it would rapidly become unaffordable / kill the network) or you will be paying a high multiple above market rates for equivalent work
There is no guarantee that any operation is repeatable, since miners can come on and off the network and no record of the algorithms they use is made
There is no guarantee that any miner is not simply passing a given request through an existing cloud service for a markup
No data passed through this mechanism can be considered private
In other words, if you and your clients are comfortable paying a large premium for non private work which may not be repeatable tomorrow at the same quality even if you have high demand, then BitTensor Compute might be right for you.
Development Platforms: Platforms such as GitHub, GitLab, and Bitbucket provide version control for code and facilitate collaborative software development.
BitTensor Development Platforms: Same problems as specified for other services, now with additional IP legal exposure due to sensitivity of proprietary code.
Web Hosting and Management: Services like WordPress, Squarespace, and Wix offer web hosting along with tools to create and manage websites without needing technical expertise in web development.
BitTensor Web Hosting and Management: Same problems as other services due to untrustable infrastructure, requirement for custom billing, centralized DNS, etc.
Virtual Desktops: Services like Amazon WorkSpaces and Citrix Workspace provide a cloud-based virtual desktop infrastructure (VDI), allowing users to access their desktop environments from anywhere.
BitTensor Virtual Desktops: Completely feasible if the customer is comfortable with random outages and probable wholesale logging of any sensitive information generated during virtual desktop sessions.
Backup and Disaster Recovery: These services, like Carbonite and Backblaze, offer online backup solutions to protect data from loss or corruption.
BitTensor Backup and Disaster Recovery: BitTensor infrastructure’s lack of guarantees seems more likely to cause your disaster than help you ameliorate it.
Content Delivery Networks (CDN): Services like Akamai, Cloudflare, and Amazon CloudFront distribute content across multiple geographical locations to improve access speed and reliability.
BitTensor CDN: Possible with a large amount of work and overhead and demonstrably inferior to just using BitTorrent, which is free. Network Management: Tools like Cisco Meraki and Aruba Central offer cloud-based network management solutions, including the management of Wi-Fi, switches, security, and mobile device management.
BitTensor Network Management: Again, possible but undesirable on untrusted infrastructure.
Security and Compliance: Services such as Symantec, McAfee, and Okta provide cloud-based security solutions for protecting data, managing identity and access, and ensuring compliance with various regulations.
BitTensor Security and Compliance: Hilariously mismatched with a system that uses completely untrustworthy infrastructure.
Integration Platforms: Tools like Zapier and MuleSoft facilitate the integration of various cloud-based services and automate workflows between them.
BitTensor Integration Platforms: Probably doable if you and your customers are targeting unreliable integrations.
Summing up the response - it is fair to say that the claim that BitTensor’s network as currently constructed will supplant any currently existing centralized alternative in a cost competitive way is implausible. Since the building blocks have no reliability guarantees by design, it is also implausible that these components could be integrated in a reliable way to produce “intelligence.”
Claim: Distributed Ownership of Machine Intelligence
“[we will] ensure that the benefits and the ownership of machine intelligence are in the hands of mere mortals.”
Response:
False if “mere mortals” is meant as a proxy for “the public.” The design of this network is explicitly against an open source ethos as code and weights are not required to be shared. Any sharing that occurs would be against the economic incentives put in place by the network. True if “mere mortals” is meant as a proxy for “the early high stake adopters of BitTensor” and said mortals are the ones primarily developing models to run on the network.
Claim: Bittensor is an Intelligence Commodity
“In summary, digital commodity incentive mechanisms are the perfect markets, and perfect markets have the amazing quality that, when aligned, they are unstoppable and unequivocally powerful… Bittensor focuses primarily on building value-creating markets.”
Response:
False. BitTensor is not building a perfect digital commodity market, and is therefore not value creating in the same sense. Let us use a commonly accepted definition of a perfect market, as follows:
A perfect market is an idealized market structure that establishes certain conditions under which firms and individuals operate. To be considered a perfect market, a number of key criteria must be met:
- Many Buyers and Sellers: There must be a large number of buyers and sellers in the market, with none of them large enough individually to influence the market price. This ensures that the market price is a result of collective market forces rather than individual control. Homogeneous Products: The products offered by different sellers should be identical or very similar, making them perfect substitutes for one another. This homogeneity ensures that consumers do not prefer one product over another based on differences in quality or features. Perfect Information: All buyers and sellers have complete and perfect knowledge about the market, including prices, quality, and availability of all products. This condition ensures that all market participants can make well-informed decisions.
- No Transaction Costs: There are no costs involved in buying or selling beyond the price of the product itself. This means no transportation costs, no information costs, and no barriers to enter or exit the market.
- Price Takers: Both buyers and sellers are price takers. They accept the market price as given and cannot influence it. This is a result of the large number of participants and the homogeneity of the product.
- Free Entry and Exit: Firms can freely enter or exit the market without any barriers. This means no significant legal, financial, or technological barriers to starting or closing a business. Non-Intervention by Governments: There is no government intervention in the form of tariffs, subsidies, or regulations that would distort market prices or competition. Let’s now apply these criteria to the classic use case for BitTensor, large language models. Applying the criteria for a perfect market to the market for large language model text outputs, these specific conditions would need to be met:
- Many Buyers and Sellers: There should be a large number of buyers (users or businesses needing text outputs) and sellers (providers of large language models) in the market. No single entity should be dominant enough to influence the price of text outputs significantly. The dominance principle is immediately violated, as BitTensor’s network design inherently favors large stakeholders, meaning that they are arbitrarily dominant in rating and thus setting rewards for text model outputs (influencing the price).
- Homogeneous Products: The text outputs from different large language model providers must be nearly identical in quality, format, and utility. This means that a text output from one provider is a perfect substitute for a text output from another provider. This is not true even in the abstract, as large language models are a ‘winner take all’ market, and some LLMs are demonstrably superior than others. Arguably, OpenAI is single handedly driving market pricing right now. There is no reason to believe this will change in the future, as people will always want to use the best model available.
- Perfect Information: All market participants should have complete and equal access to information about the various large language models available, including their capabilities, limitations, pricing, and any other relevant details. There should be no information asymmetry between buyers and sellers. This is not true on BitTensor, as model information is not shared on the network and is completely off chain. On BitTensor, no one knows what another miner’s overhead is, what model is being used, or anything about any capabilities and limitations of any model being used. Since agreement among validators is required for validators to function, validators cannot even reward niches or specialize within a subnetwork.
- No Transaction Costs: There should be minimal or no costs associated with acquiring or providing text outputs beyond the price of the service itself. This implies no significant barriers to using different large language model services, such as compatibility issues, complex setup requirements, or hidden fees. This is not true on BitTensor, as from a customer standpoint, there is a high effective cost as the customer must scrutinize each output to see if it is acceptable or merely “the best of a bad lot” that a validator looked at. This is in addition to the fact that an (N+V) multiple of the required calculations are run in order to satisfy BitTensor’s algorithm, which adds an inherent transaction cost as compared to simply running the model on a single instance of rented hardware.
- Price Takers: Both buyers and sellers of text outputs should be price takers. They accept the market-determined price for text outputs and cannot individually influence this price due to the high competition and product homogeneity. There is no way for a buyer of text outputs to choose a provider as these are arbitrarily decided by validators. Buyers can however directly influence the price of text outputs by staking Tao with a given subnetwork, thus increasing the rewards distributed to miners; this criterion is violated.
- Free Entry and Exit: New providers of large language models should be able to enter the market without significant barriers. Similarly, existing providers should be able to exit the market without facing prohibitive costs or legal barriers. This means minimal regulatory, technological, and financial barriers to entry and exit.
This is not true on BitTensor either. There is an effective buy-in fee for miners to enter both literally, and also in the sense that there may be low utilization of their hardware until they are deemed ‘trustworthy’ (which may never happen, depending on how verifiers are coded).
Non-Intervention by Governments: The market should operate without government interventions like subsidies for certain providers, tariffs on text outputs, or regulations that significantly favor certain providers over others.
This is untested. Summing it up, it is not believable to claim that BitTensor is a perfect market. BitTensor is an opaque market that does not comply with their stated definitions.
Claim: TAO is transferable
Tao is transferable
Response:
True.
Claim: TAO is Censorship Resistant
Tao is a censorship resistant token
Response: False. Let’s define a censorship resistant token as follows: A censorship-resistant token in the context of cryptocurrency shall refer to a digital asset that is designed to be immune or highly resistant to censorship from any centralized authority, such as governments, financial institutions, or any single entity. The key characteristics of such a token include:
- Decentralization: The token operates on a decentralized network, typically a blockchain, which is maintained by a distributed group of nodes (computers) rather than a centralized organization. This decentralization ensures that no single entity has control over the network, making it difficult for any one party to censor transactions or freeze assets.
- Permissionless: The token can be accessed and used by anyone without the need for authorization from a central authority. This means that users can participate in the network, send and receive tokens, or engage in smart contracts irrespective of their location, identity, or political standing.
- Transparency and Immutability: Transactions involving the token are recorded on a public ledger, which is transparent and immutable. Once a transaction is added to the blockchain, it cannot be altered or deleted, which prevents any form of retroactive censorship.
- Resistance to Regulatory Actions: Censorship-resistant tokens are designed to withstand attempts by governments or regulatory bodies to control or shut down the network. This is often achieved through the use of technologies like cryptographic encryption and smart contracts, which enforce rules and execute transactions automatically without the need for intermediaries.
- Anonymity or Pseudonymity: The ability to transact anonymously or under a pseudonym can be a feature of such tokens, providing users with privacy and further protection against censorship. The Tao coin is controlled, in practice, by its parent foundation. The parent foundation claims it will divest control of the coin, but has not done so. Thus, Tao cannot be claimed to be “Decentralized,” as any government in the world could put pressure on Tao’s known principals. Furthermore, the work of transactions primarily occurs off chain. Thus, transactions are not transparent and immutable. They could be said to be immutable if one considers only the blockchain aspect of BitTensor, but this is not what is being advertised as being useful. Finally, BitTensor does not in its framework offer cryptographic primitives or obfuscate its network membership. Thus, it cannot be said to be particularly resistant to regulatory actions, or particularly “anonymous” out of the box.
In conclusion, it is a stretch to call BitTensor “censorship resistant” based on its centralized ownership / governance, and approach to transactions and membership.
Claim: Auditability
The BitTensor network is auditable
Response: In a literal sense for what it captures, yes, but not in a useful way for miners, validators or customers. As mentioned earlier, transactions mostly occur off chain with a minimal “value was created” record after the fact. It would be impossible for a customer or any other participant to use on-chain information to reconstruct the activity associated with a transaction. Therefore transactions (and incentive issuances) are effectively not auditable.
Claim: Transparency
The BitTensor network is transparent
Response: Not really, no. See all previous discussions.
Claim: Effective ML Models
BitTensor provides an efficient and objective way to evaluate ML model performance
Response: BitTensor does provide an objective way for a validator to evaluate model performance; it requires that such evaluations occur totally unsupervised. It is not a particularly efficient way to evaluate performance for several reasons: Evaluations must be performed on the results of every query as responses cannot be assumed to meet some baseline definition of ‘good enough’ Evaluations of novel responses can only stack rank responses against each other, and therefore a minimum number of responses must be collected (usually 3) Evaluations of novel responses require that a validator be sophisticated enough to distinguish amongst responses, which implies a computationally intensive validator that is reading in a potentially very large number of tokens per query depending on the number of responses collected and the size of said responses. There is also an unstated implication that an effective validator must be greater than or equal to any given miner in terms of its capabilities.
Claim: MOE Architecture
BitTensor’s AI layer is a mixture of experts architecture.
Response: It can be. It’s entirely optional and depends on how the subnetwork validators query miners. It is not a default feature of the network as it is something the tutorial on large language models has to explicitly implement.
Claim: “The Bittensor team is now training more sophisticated models directly on the Bittensor protocol to work towards achieving performance comparable to current state of the art models.” Response:
It seems unlikely. The protocol as specified has insufficient bandwidth to facilitate the training of a very large competitive model, and BitTensor includes no primitives for sharded training with weights being shared back. Therefore, if there is an effort underway, it would have to be on a classical GPU cluster that is under BitTensor’s control, which would violate the ‘spirit’ of this statement in the sense of it not being a community driven effort, if perhaps not the letter. Evaluation of published validator / miner code does not turn up any sharded training approaches.
Claim: Game Theory Optimal AI Weighting
“The solution is an incentive mechanism that maximally rewards honestly selected weights, making the system resistant to collusion of up to 50 percent of the network weight. The result is a collectively run intelligence market that continually produces newly trained models and pays contributors who create information theoretic value.” Response: As previously discussed, attacks can easily be run at the subnet level by overwhelming the current staking in the subnet. There is also no reliable way to distinguish honest from dishonest miners, which makes attacks easier to pull off.
Claim:
“By changing the basis against which machine intelligence is measured, (1) the market can reward intelligence that is applicable to a much larger set of objectives, (2) legacy systems can be monetized for their unique value, and (3) smaller diverse systems can find niches within a much higher resolution reward landscape.”
Response: In practice, the more ‘niche’ an application is, the more attackable its corresponding subnet is because the amount of Tao staked in that subnet can be more easily overcome. Thus, this is false. The ‘unique value’ of legacy systems is unspecified, but in general people do not run obsolete ML models for fun, they run current ML models to solve problems. Thus, this claim is dubious. As discussed, this is only true if niches can withstand attacks and generate some sort of premium over generalist models. If niches are attacked and thus produce poor results, it is hard to see how they will be economically viable.
Claim: Algorithmic Model Weighting
BitTensor rewards good models and punishes bad models.
Response: There is no inherent reason for this to be true, as:
Model evaluations are difficult and only as good as the validator model The network design rewards collusion by rewarding similar verification ‘scores’ Validation is a popularity contest weighted by stake, and popularity is not the same as correctness
Claim: Efficient and Robust Model Pruning
BitTensor is resilient to models dropping off the network
Response: Not really. There are theoretical approaches (one of which, distillation, is discussed) that could help a bit, but the network doesn’t have any primitives or particular advantages over the status quo, or, as far as I can tell, any implementation of the theoretical approaches it suggests. BitTensor makes a lot of grand claims and seems a bit too early in their implementation process (to put it gently) - for us to underwrite the valuation case of replacing OpenAI or bringing forth transcendent machine intelligence Overall, the network’s design does not align with its stated value proposition and thus is difficult to recommend.
In What World would Tao be valuable?
Tao has made a lot of unsubstantiated claims about effects arising from their network design. But let’s give them the benefit of the doubt. Let’s imagine either Tao changes or the world changes such that Tao becomes incredibly valuable. What would those changes look like?
- ML models in different domains plateau in performance In this world, open source models reach GPT4/4V level performance on modest hardware in the next year. It turns out ML models cannot be improved beyond this point. OpenAI, Microsoft, and Anthropic, etc. are stuck in a race to the bottom in terms of price / performance, and a vibrant market of privately run models springs up. Now we enter what is in fact a perfect digital market, because everyone’s capabilities are known because everyone’s capabilities are the same. Of course, in this race to the bottom world, any performance overhead becomes a serious disadvantage, but perhaps pseudo-anonymity trumps that for some.
- Tao’s parent foundation decides that running fundamental operations like storage on subnetworks is not a good idea, and just uses the polkadot substrate to bridge to dedicated networks that are actually fit to purpose. In this instance, a lot of the deficiencies of the subnetworks are ameliorated, and it’s possible some useful applications arise from Tao’s framework once the building blocks are solidified
- Tao changes its design so that model provenance, execution, and weights must be public and writes a really friendly api to enable distributed training based on cutting edge sharding techniques. In this case, Tao could become a de facto standard platform for training large models on distributed hardware.
- An extraordinarily capable model appears only on the Tao network and nowhere else. Everyone rushes to use this model despite its unknown provenance, because it seems even more capable than GPT4. The economic inflows encourage Tao to build more primitives on its network to make trusted computing on it viable.
Unfortunately we do not see a high % chance of these things occurring at the current juncture
What World is the Current Network Design Likely To Foster?
As discussed in previous sections, the current network has the following difficulties:
- No real solid foundation to build on as all computing is untrustworthy, or at least not provably trustworthy
- Niche subnets are more easier to attack than mainstream subnets
- “Trust” mechanism actually encourages cabals
- Inherent network overhead associated with validation means BitTensor will never be the most efficient place to execute a given operation
- No way to really know if incentives are being apportioned as stated (different code can be running than what is stated)
- Customer connection for customers not owning Tao must be built via cumbersome bridging mechanisms; customers != validators in most instances so customer preferences cannot be directly expressed
- Subnetwork design is by fiat rather than based on product market fit and subnetwork establishment is costly, so subnets are unlikely to arise organically
Taken together, these difficulties suggest that:
- The only important factor for subnetwork success is staking which is equal to high net worth investor stakes + ongoing popularity via stake delegation, therefore: Popularity and belief will drive inflows into subnetworks, as economically useful outcomes are not attainable with BitTensor’s high overhead
- Social promotion and frenzied memetic activity will rule the day as most consumers are not machine learning or crypto professionals; Tao subnetworks become parlors within a casino
- Tasks chosen by subnetworks will be ‘toy’ tasks designed to be illustrative of some nebulous potential rather than economically useful, the more to appeal to the masses
- Popular validators will emergently form cabals and attempt to monopolize traffic as it is no one’s interest to have additional validators join
- Popular validators will copy each other’s answers directly if possible via creative use of timing attacks, or come up with off chain mechanisms for coordination, as validation work impairs profitability
- Miners not running absolute state-of-the-art models will either be downranked and booted or randomly allocated tokens as validators maximizing profits don’t actually care about result quality
- Miners will attempt to form off-chain cabals to copy each other’s answers as this is will always be more cost effective than one miner paying full freight for say, a GPT4 Turbo passthrough
- Validators will form financial arrangements with miners (or run miners themselves) and will disproportionately reward favored miners even when disfavored miners are producing better answers; this will be done at just the rate so as not to cause wholesale attrition and is perfectly deniable as the code validators are running is opaque
- As the hype cycle dies down and inflows from naive new miners and validators decrease, subnets and cabals will consolidate amid vicious infighting
- No useful advances in machine learning will be achieved as a result of any of this
Making Money on Tao
Even if we don’t particularly believe in the roadmap of the BitTensor network or think it’s going to lead to positive expected value for most participants, that’s not to say we can’t make money on it today. Let’s review some basic scenarios that would enable this:
- We run a high quality model at low cost that puts us at parity with other miners because they are unlikely to do better for cheaper. If we pick a subnetwork that has a high stake, it’s possible that the rewards we get will outweigh our costs. For example, let’s imagine that we simply do a passthrough to the GPT4Turbo API with our miner and maybe a custom prompt to make it slightly better than the “out of the box” experience. If our model wins against inferior models, and wins against other GPT4 passthroughs, and our per token cost is low, then we could make some money.
- We run a model arbitrage play that iteratively determines the lowest cost model across many cloud services that still has an acceptable win rate for a given subnetwork. We then run this all day every day until the statistics change, and then we switch accordingly.
- We could find populator validators and delegate our stake to them. This will get us a proportional 78% of our proportion of the reward they get issued. As outlined on the delegation docs here
- We run a validator ourselves, and can get similar results to other validators with low overhead perhaps by coordinating with them. In order to make our validator more prominent and likely to attract stake, we promote it heavily on social media and perhaps even do cross promotions with other members of our collective
- We farm airdrops from as many hype social media promotions of subnets as we possibly can, as outlined here
- We provide a subnet that attempts to compensate for some of the core difficulties associated with the network, while quietly favoring our collective. For example, let’s say we build a ‘trust evaluator’ subnet that scores miners and validators independently as a client of each. Stake could be used as a competitive differentiator
- We run a large number of legitimate validators for six months, accumulating a large amount of stake. Eliminate every other competing validator on the subnet. Profit.
- We run a large number of legitimate validators or one really big validator for six months, and then change the validator code to run a more “value oriented” algorithm in agreement with a collective of other validators. Same as above, but we favor our own collective’s miners at a rate that makes them the most profitable
- We create a highly popular subnet that, for example, directly rather than indirectly facilitates gambling of some kind. Lottery tickets are the easiest but least interesting version of this, prediction markets for many different things are already emerging. Since everyone is already gambling anyway, this is highly appealing, and comes with the benefit that if outcomes are unguessable, miner compute requirements are inherently low, and if outcomes are guessable, as a popular validator you can potentially front run the market or the event by getting useful predictions before anyone else does.
- At the current valuation level which feels stretched, these high alpha implementations feel a more appropriate means to achieve TAO price exposure.
Conclusion
Given that TAO has been paraded around by a large number of people as the primary AI coin - it seems increasingly important for us to due dilligence these coins before making substantial long term investments.
If we are right about our fundamental thesis that machine intelligence accrues financial value on chain, this is not about “pumpability” or “narrative” as much as it is about tokenomics, network functionality and factors that crypto native investors have paid less heed to in past cycles.
We hope you enjoyed our report. If you have feedback, e-mail [email protected] and remember to subscribe to get these by email