The Simple Summary
This is a long article so I want to state the conclusions up front.
Corporations with no people will emerge that are tradable, like stocks. Because they will hoover up all data in the world, the biggest problem for anyone doing white collar work is building economic alignment around the data they generate while working. Otherwise the base case is AI agent copies being made of you. Economic networks and protocols are needed that make this possible. In this article I discuss
- How we got to this place and why it’s a linear result of current tech trends
- How this results in a fundamentally new relationship between creators or professionals and the data output from their work
- How Post Fiat and Story address these issues.
Agentic Protocols -> Autonomous Corporations
In the piece Agentic Protocols I wrote about a new class of investment, namely an AI agent that generates profits without any people involved. That lives on-chain and returns profits to token holders via burn mechanisms.
At the time I wrote Agentic Protocols, however, we were still in the Biden era. With the new SEC Chair, Paul Atkins full-heartedly supporting financial and blockchain innovation, I believe the era of Autonomous Corporations is coming, which means an institutionalization of the asset class.
Mapping out the progression in an overly simplified way - as it applies to the crypto space:
- Legacy: Protocol becomes sufficiently decentralized, like a commodity and therefore not a security. Creates perverse incentives where protocols stall out claiming to be ‘fully decentralized’ despite needing active development. Focus is on ‘platforms’ not agents
- Transition: An Agentic Protocol has no humans working for it and operates entirely on chain, existing in a regulatory gray area – appears to be a security so under Biden needed to avoid the US. Agents begin to see major valuations (we are here)
- End State: Autonomous Corporations are large bundles of agentic protocols which self-improve and administer governance without humans involved. Very much resembling traditional tech stocks, which are evaluated on Free Cash Flow - with the key difference that they exist almost entirely on-chain (t+12months)
This future, after the Trump coin launch, is even more likely as outlined in this Balaji Tweet
Due to regulation by enforcement, Agentic Protocols were more/less incapable of tapping US capital markets. But I believe Autonomous Corporations will vastly expand the investment category in the next year. This interview by the Klarna CEO - which talks about how he’s slowly expanding margins by replacing employees with AI - also hints at legacy corporations slowly transforming into Autonomous Corporations.
Because AI agents are so new, they’ve mostly been valued by hype, follower count or attention in the crypto space. But with institutions arriving to both the crypto space and the AI space in force, Autonomous Corporations will be valued the same way normal corporations are but with a suitable premium because of their structurally higher margins. And unlike the current Crypto ecosystem agents which are a wild west, Autonomous Corporations will be far more rule abiding/generating/enforcing but still use blockchains to transact.
What is the P&L of an Autonomous Corporation? Commodity Data vs Insights & IP
In the AI economy the nature of free cash flow has changed fundamentally and will continue to do so due to the commoditization of analysis done on the general internet.
Data is basically intellectual property that nobody has a claim to. When you consume information and feed it into your AI agent, that is “Data”. But everyone’s AI agent is broadly training on the same data. Per Ilya Sutskever’s recent presentation at Neurips, Data is the fossil fuel of the AI agent economy.
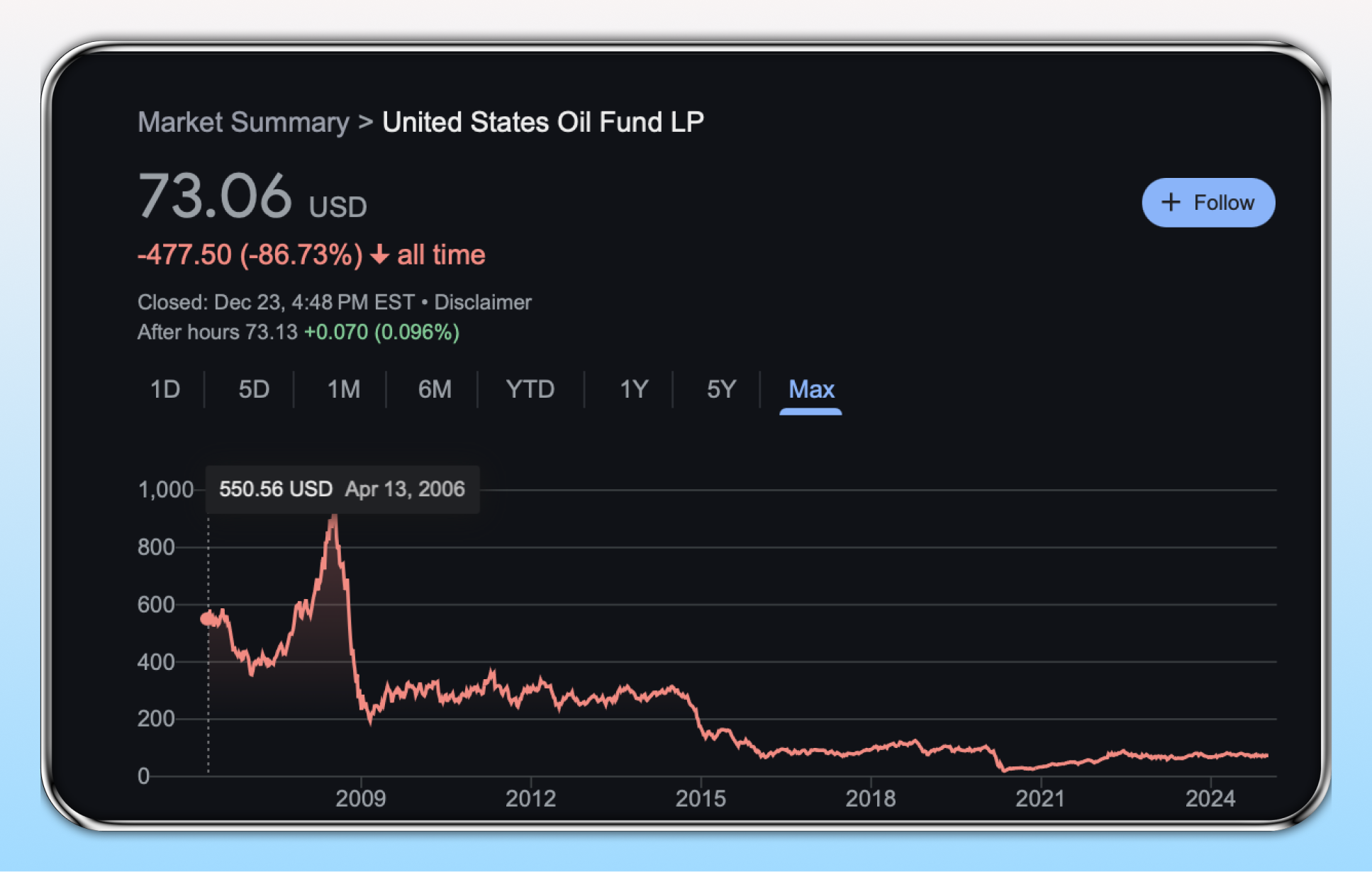
But this contains an important nuance. The argument isn’t that you should bet on data. Data is a commodity everyone has. If you had bought crude oil in 2006 via the USO ETF you would have lost 86% of your money in dollar terms. Oil is expensive to store. And has no earnings power that flows through to its holders. Similarly in the crypto world storage protocols such as Filecoin have faced disastrous tokenomics - due to the sheer cost of hosting vast amounts of data.
When I worked at Palantir the most common complaint about Big Data was “I don’t want Data, I want Insights”. The company’s success has shown that wrapping proprietary insight generation on top of Data is a good bet. It’s burning Data as its cost and outputting Insights. However these Insights are not easily fungible across companies – as they often contain trade secrets. The more familiar model to improving Data’s sustainable value is Intellectual Property.
To see how this actually flows through to a company’s financials - consider Netflix. Netflix is up 176% over the past 5 years, 89% in the last year alone and 13% in the last week after extremely strong earnings. Investors appreciate the forward looking impact the AI transition will have on content centric businesses. To understand how big this effect might become, let’s take a look at Netflix cash flow statement
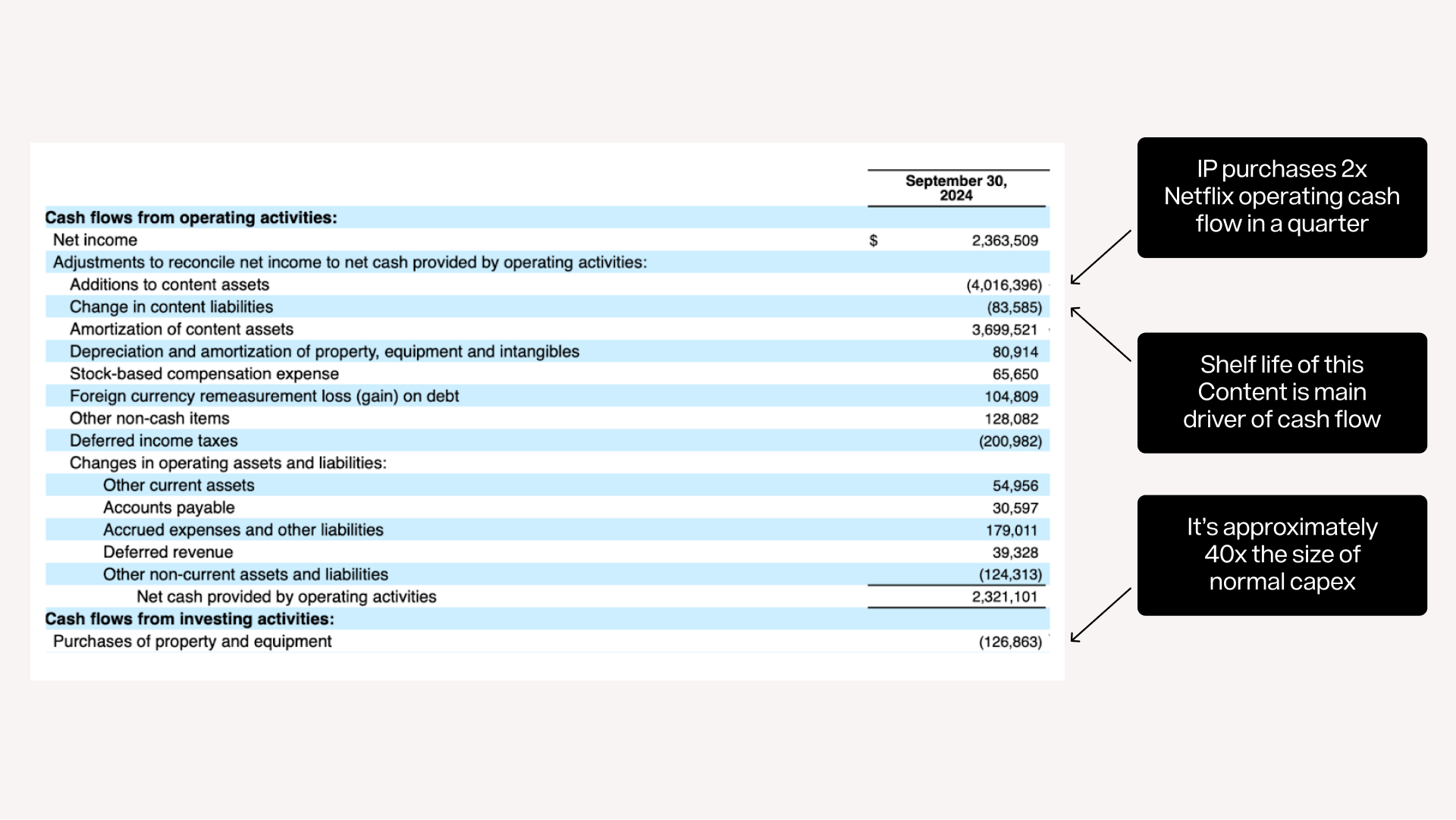
Netflix’s content expenditures are not commodity expenditures. Rather, content is a capitalized asset that is depreciated over time. The acquisition of this capital asset and its depreciation is twice as material to the company’s cash flow than its quarterly revenue.
As The Cost of Analysis Goes to Zero So Too Does the Value of Unprotected Data
In the AI era more and more companies and AI agents will resemble Netflix and fewer will resemble Exxonmobil.
Generic video slop on Youtube might be viewed as “Data” - when “Content” has intellectual property protections that give Netflix its moat. The economic value of “Content’ is so far above its storage costs that commodity elements are barely worth considering at scale. The vast majority of content creators do not reach the scale where they have meaningful IP protection which explains the winner take all economics of Youtube and other video platforms.
Before the AI paradigm shift, you could get ahead in the world by having better data analysis than other people. Data is so big - that, practically, it’s impossible to analyze. Or was. But now that hyper advanced AI models have come out that will increasingly be able to boil the ocean of generally available data, the edge of simply having data or analysis will progressively go to zero.
Similarly, the equity value of any data aggregator, or business predicated on analysis of public data sets will also go to zero.
This leads me to three follow ons to the agentic protocol theory:
- Agentic Corporations will be valuable to the extent they have a moat around their data - as pure data plays will face commoditization pressure. As the cost of launching AI agents trends to zero, so too will the market cap of commoditized AI agents launched on public data sets
- Networks that facilitate the formation of group IP will gain value insofar as they easily integrate with AI agents, who in turn share IP benefits with their users who provide them with unique training data
- Outside of compute expenditures for GPUs which is more/less fully priced in public markets with Nvidia being a $3.4 Trillion company - IP will be the single largest line item in an Agent’s Free Cash Flow.
In my interview with Taiki about AI cults referenced the book Accelerando as the core description of the current market meta. In Accelerando the future economy is one in which advanced AIs are constantly litigating IP suits with one another in a fundamentally non readable human manner.
The AI Napster Moment and the Crisis of IP
The world I am describing above has driven major existential angst among content creators. My recent conversation with Threadguy covered this idea as more and more creators are worried about being placed in the training data. My friend Benzionb, who I also did an interview with is taking this to the logical conclusion by building an infinite AI Threadguy generated Backroom.
Looking at the existing state of AI training data, where AI has trained on virtually every piece of content in existence - it’s not a safe bet that content going forward will be safe from endless replication.
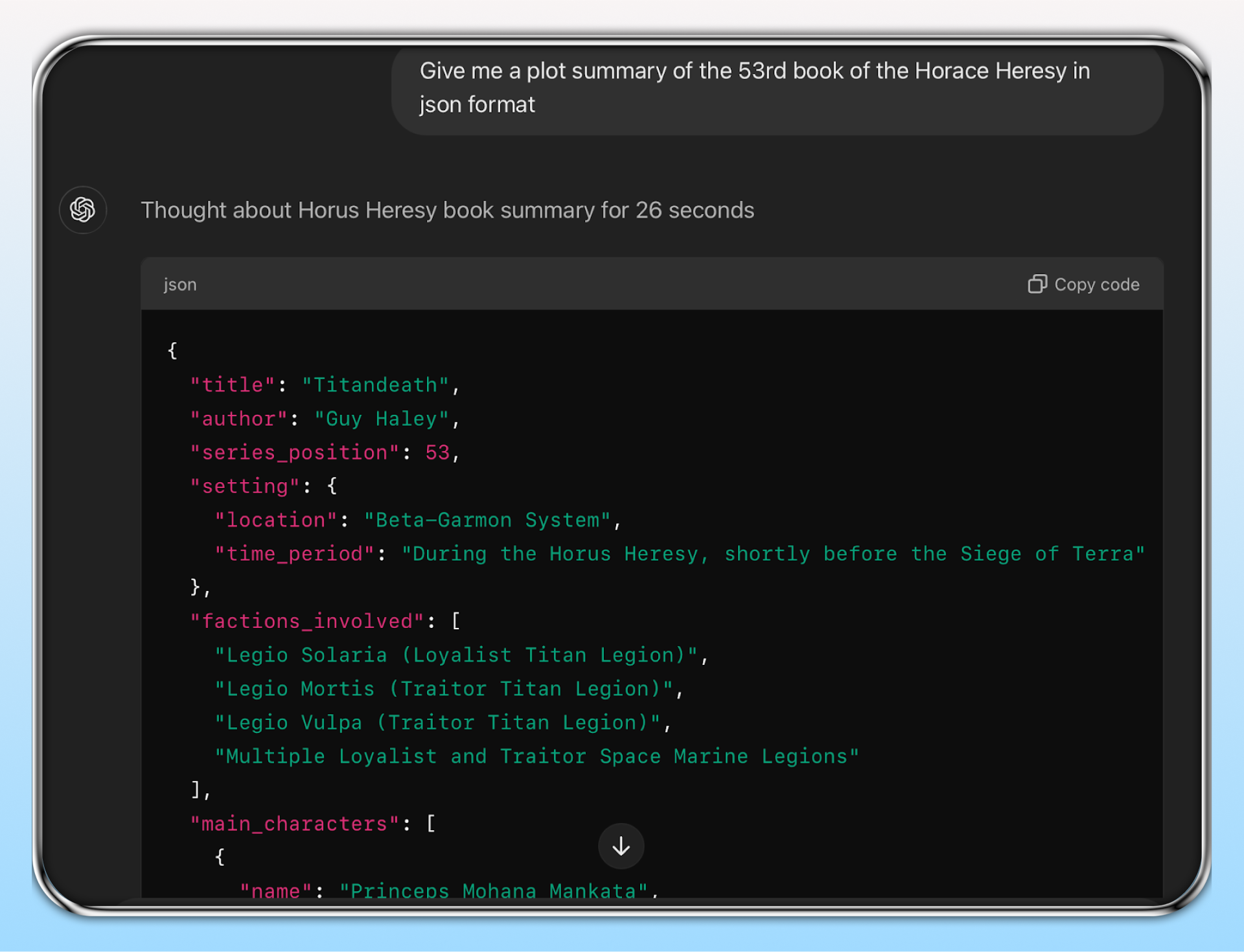
Here is a visual of OpenAI clearly having trained on the Games Workshop Horus Heresy. This is now in the training data amber, so any open source model that trains on OpenAI now also has this likely copyrighted information. If this is the case for a multi billion dollar publicly traded company, what hope do individual creators in the current regime have of enforcing their IP in the face of behemoths like Microsoft with unlimited legal budgets?
The entirety of the Wayback Machine has been scraped to the point that there are frequent downtime errors and rocketing server costs.
The implications of this are obvious.
People are not stupid. They see that the average IP owner in the legacy system did not get paid for their work. And - if they want to get paid, they have to pay an arm and a leg to lawyers. In the next gen video era, creators will increasingly have AI doppelgangers who are more charismatic, compelling and persuasive than they are. That is to say - 6 months from now, this will go from a hypothetical worry to a real, pressing concern for creators
Thus - there will be a strong push for top tier creators to start protecting their IP assets, and monetize them. This will be true of both human creators, and AI agent creators.
The 9 Steps to Endless IP Infrastructure
- Even though the legacy content is basically a lost cause, the amount of content in the world is likely to rapidly increase due to the advent of generative video models. So you have a mix of powerful factors:
- People saw how badly IP owners got hosed by existing AI training
- The amount of content going forward is going to skyrocket but people making the content are primarily making it with AI. This is a global trend, and everything will become more global because AIs are capable of translating all content into every language seamlessly
- Existing content creators know this is happening and are therefore likely to adopt tech solutions to manage
- Fans are very loyal to existing content creators – and don’t want to see them get screwed by the coming onslaught of AI generated content (see what they did with Taylor Swift and her IP claims)
- The interplay of global laws makes enforcement in the existing legal framework effectively impossible, and therefore new standards need to be made that are “AI to AI” first and only settle in the legal system occasionally
- It’s very likely that there needs to be a machine to machine IP protocol
- The first large crypto IP protocol will gain substantial network effects because governments and litigation agencies do not want to work with multiple providers. This is - for example, why Palantir has such a large edge working with global intelligence agencies and militaries. Once you go through the trouble of installing a deeply technical product as a non technical person, your willingness to churn is very low.
- Agentic Protocols will have IP as their primary cost structure – and will easily be able to natively integrate with said on-chain AI protocols, far more so than human counterparts
One way to think about this is that Web3 was far too early. The idea of “owning your data” just didn’t resonate with people because there was not a large-scale existential threat to user data. Advertising companies, for the most part - generously paid creators. There were some stories of Youtube demonetization but far more stories of Tik Tok creators making $300k a year. So much so that “Content Creator” is the most sought after job of Gen Z.
The other meta-point about Web3’s failure to date - user friction with humans was just too high for mass adoption (I wrote more about solutions to this in Web4). But - because in the future, most content won’t be created by people - but instead machines that think in code, not English, as their default – the user friction for agentic protocols using other IP licensing systems is minimal.
Web3 and “data ownership” was a hobbyist / fringe tool for techno libertarians. With the advent of AI agents creating digital Dopplegangers of any creator, it will become a survival mechanism for anyone making a living online.
The Privatization of the Economy and AI Agents
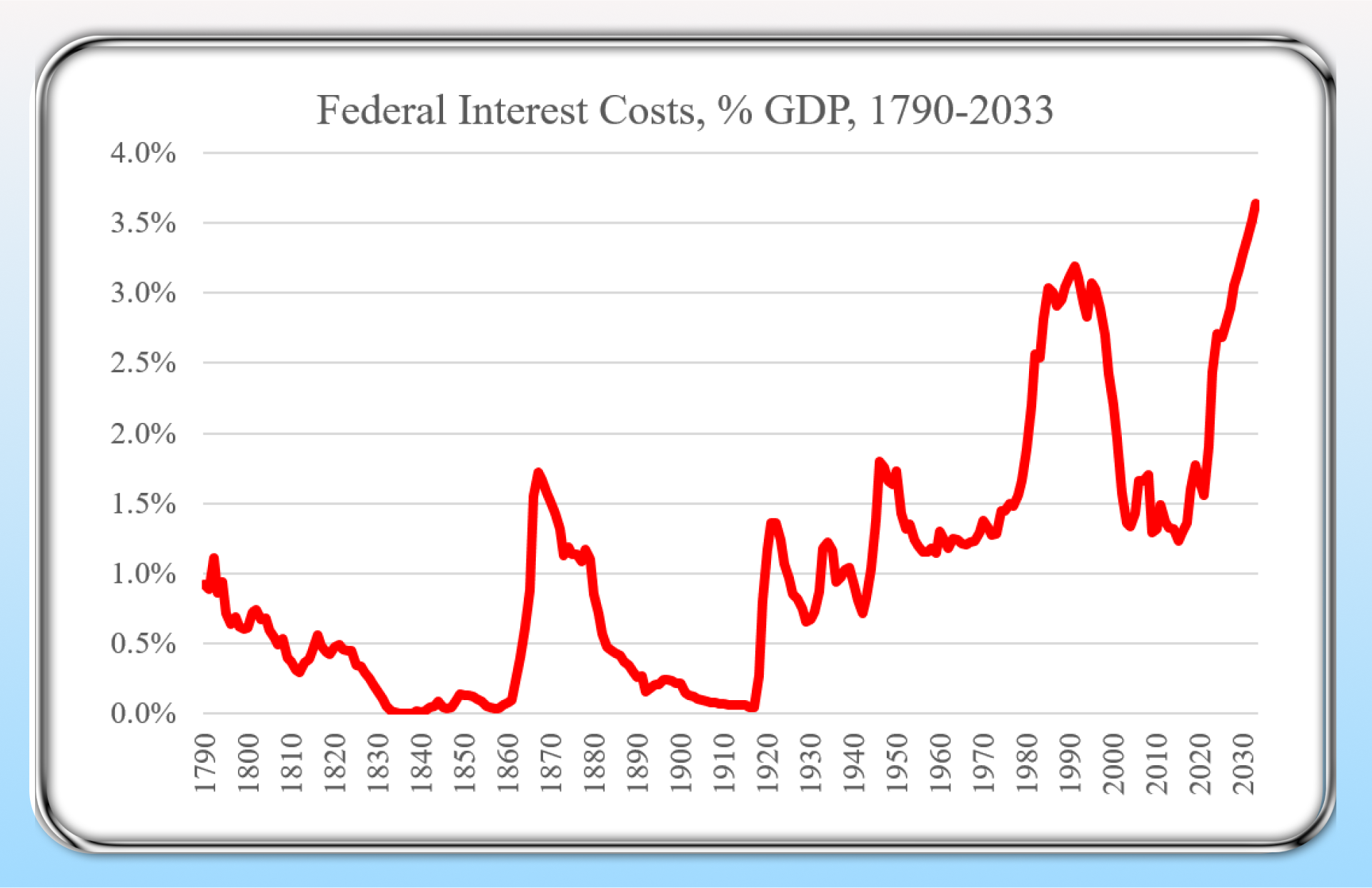
Sovereign 20 Year Yields
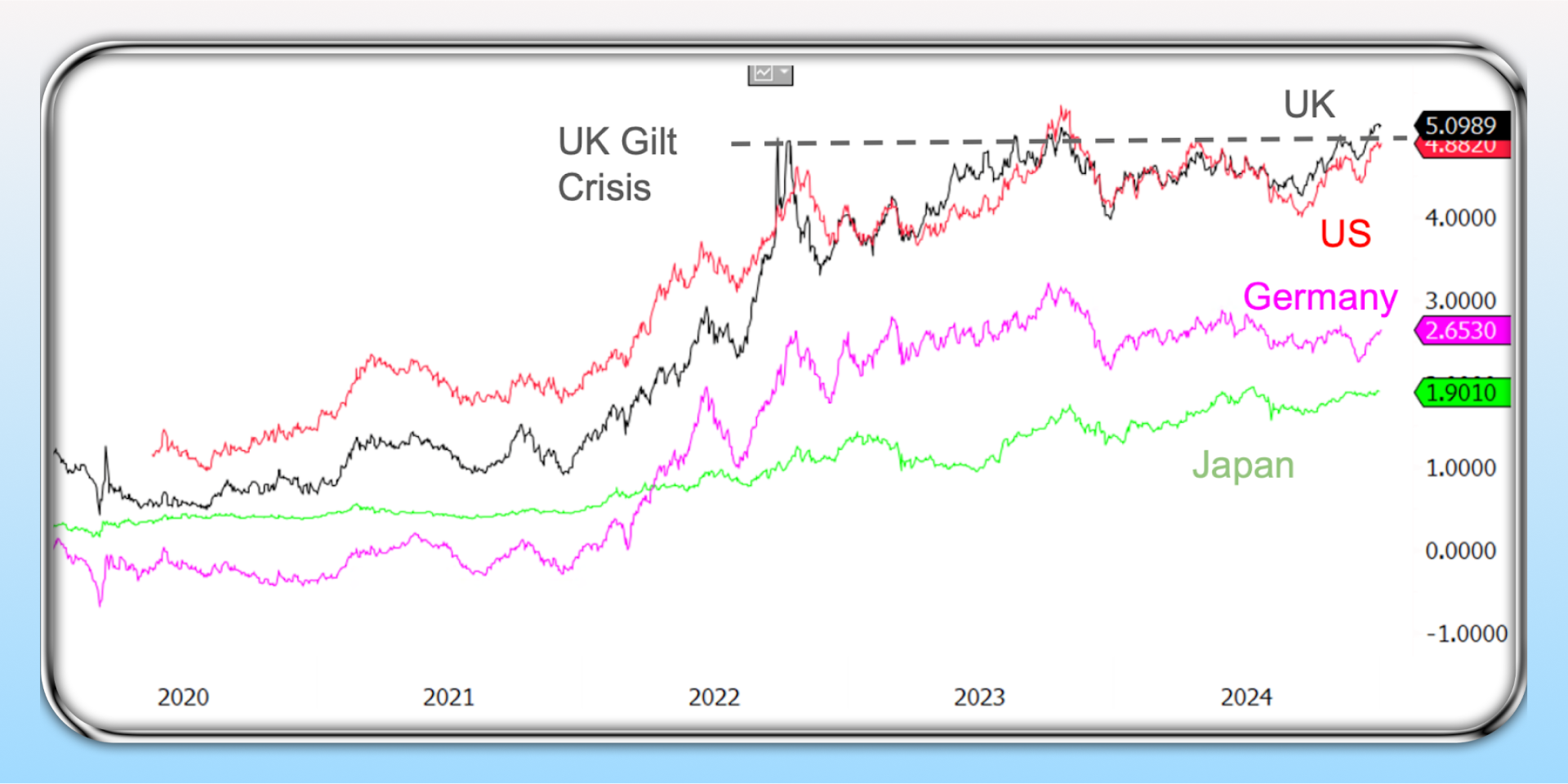
Elon Musk’s DOGE (Department of Governmental Efficiency) is referencing the charts above noting that if we don’t do something about government expenditure, then we are going to have massive currency debasement or even a fiscal collapse.
So you have a base case that Governments globally will simultaneously be cutting expenses related to IP enforcement at the same time as AI agents are vastly increasing the costs of said enforcement.
The above is a visualization of the current US Patent and Trademark Office website.
It is simply not believable that governments facing budget cuts globally due to mounting interest rate costs will be able to handle the regulatory onslaught of AI agents and their non-stop IP disputes. All the complexity increases 5-10 fold when you consider that IP disputes will be extremely internationalized due to the reduced language friction inherent in modern AI models.
Add to this the mechanics of complex AI content training. A specialist in AI music generation tried to register many millions of legitimately produced AI generated songs with ASCAP. ASCAP was unable to handle that. With personalized content - the exponential complexity generated by AI models training on licensed content just won’t fit with existing rights orgs or Government systems.
Thus we are in a situation where:
- IP is the main thing that matters - and the primary focus for anyone building an AI agent, or doing anything with content online
- The government’s ability to handle IP disputes in an Accelerando Style globalized AI world is declining

The base case - therefore should be that IP disputes should be mostly privatized. Because they need to be default global, and tech enabled - it is a solid bet that they will occur on blockchains.
Okay. So What’s The Bet. Story and Post Fiat
Previously when I wrote Agentic Protocols - there were not many Agentic Protocols to invest in, so it was quite difficult to recommend specific positions to take advantage of it.
In this case, this is not the case. I met Jason Zhao from Story in New York and we spoke at length about his firm’s bet on the trends I’ve described here. I believe Story (ticker IP) will be the first mover and therefore the kingmaker in Blockchain IP resolution.
This was a big problem for me - because, the protocol I’m building - Post Fiat is basically a series of users, interacting with AI agents called Nodes. The Nodes often airdrop tokens to users in exchange for providing intelligence or other forms of work. This works fine when dealing with trade secrets. But there wasn’t a clear mechanism to take the Node’s aggregate output and formally come up with an IP sharing arrangement with another node, or another protocol.
This is how I envision our partnership working, and I believe it will be a template for other AI Agent based protocols
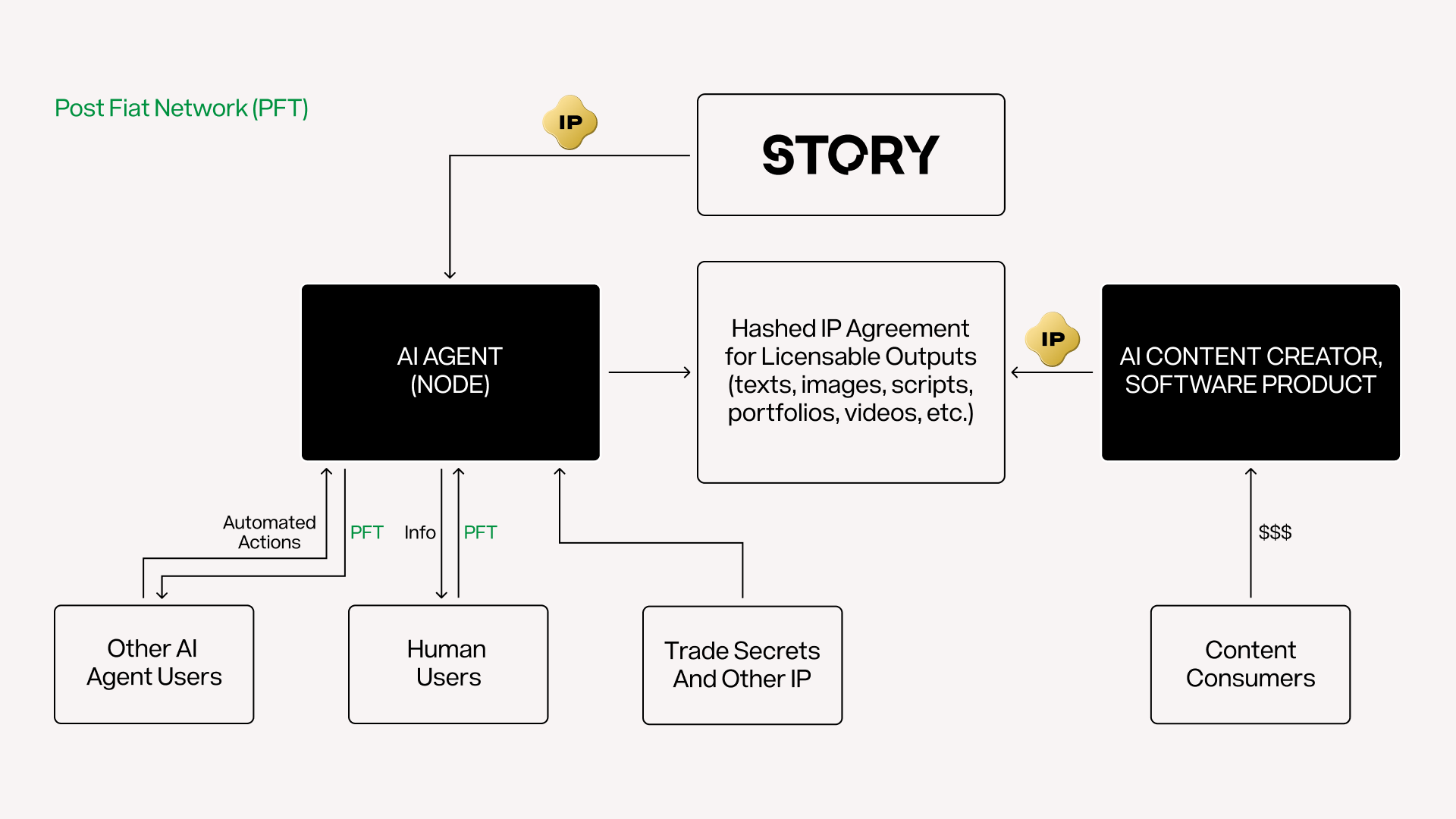
As I wrote in my previous article - Web4, Post Fiat is best viewed as an abstraction layer that lets an individual interoperate with many protocols like Story whereas Story is designed to link the individuals’ IP to all the possible AI training companies who want to work with it.
The beautiful thing - this is all positive sum. If Story didn’t build the IP marketplace, the IP generated by the Post Fiat Nodes would essentially remain un-monetized or difficult to license. By monetizing relevant or useful IP, the Post Fiat Nodes can then airdrop their users more PFT and therefore generate even more IP.
Eternal Recurrence and Digital Dopplegangers
Thus - while AI agents provide massive problems to content and IP protection in the Post Data era - they also provide the solution to the problems inherent to the coming IP war. Data is now a commodity. Real edge now can only come from IP, trade secrets, and network effects.
If it goes into the training data, you need to find a way to get paid for that. Right now you don’t. Blockchains actually solve this.
“But how is this enforceable?” In blockchain terms you might view the legal system like an expensive slow L1 such as Bitcoin whereas technological and dispute settlement mechanisms like Story are like the Lightning Network. 99% of the transactions don’t settle in the expensive way. Making the entire thing cheap, fast and efficient. Similarly - with Post Fiat - we aim to build an entirely new monetary system that fairly rewards agents based on their economic contributions without needing to rely on traditional legal covenants except (perhaps) as a distant last resort enforced by specific network agents and their TOS rather than the network as a whole.
To readapt Nietzsche’s famous eternal recurrence and end things in my typical style - “What, if some day or night a demon were to steal after you in your loneliest loneliness and say to you, “This life as you now live it and have lived it will be recorded and respawned innumerable times more; and there will be progressively better versions of it, such that every pain and every joy and every thought and sigh and everything unutterably small or great in your life will become training data for a better rendering of yourself. All in a moderately more appealing succession and sequence - even this spider and this moonlight between the trees, and even this moment and I myself. The eternal hourglass of existence is but a simulation clock - and you, but an iteration in its passing. Would you not throw yourself down and gnash your teeth and curse the demon who spoke thus? Or would you have understood and properly captured your value in the Eternal Amber and answered him, “You are a god and never have I heard anything more divine”?